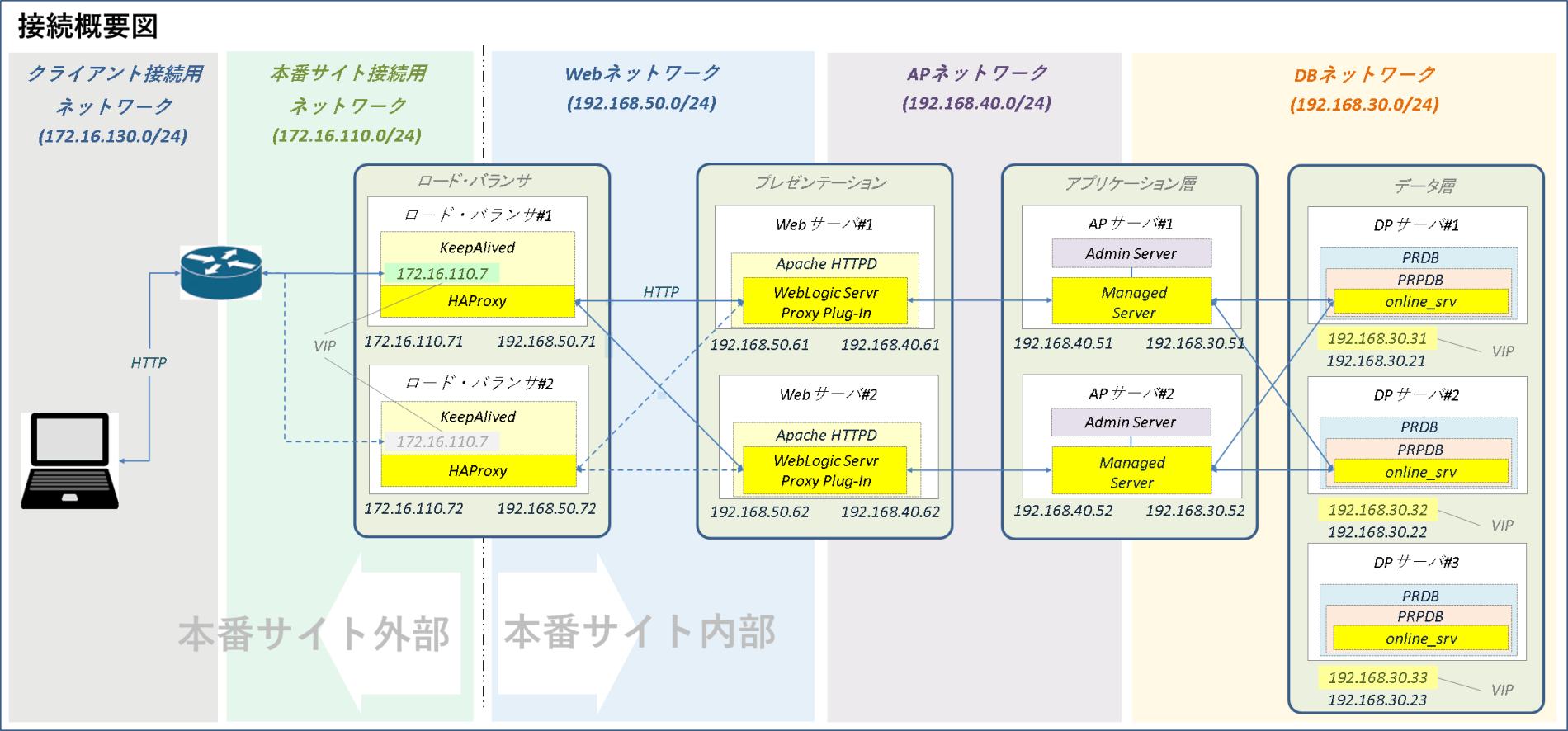
ロード・バランサ構成
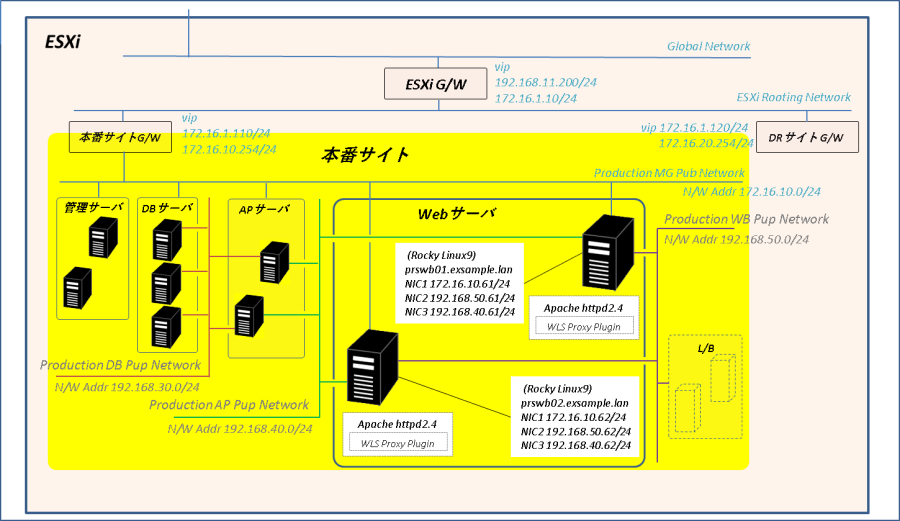
全体構成
HAProxyとKeepalivedを使用して 2台のLinuxサーバで本番サイトのロード・バランサを構築します。APサーバと同じくデストリビューションにRHELを使用する要件はないのでOSはRocky Linux(v9.5)です。
まあ、現実には専用のN/W機器で本番システムのロード・バランサを構築するでしょうからここはあんまりあんまりガッツリ設定入れないで基本的なバランシングの機能だけで済ませてしまおうと思います。
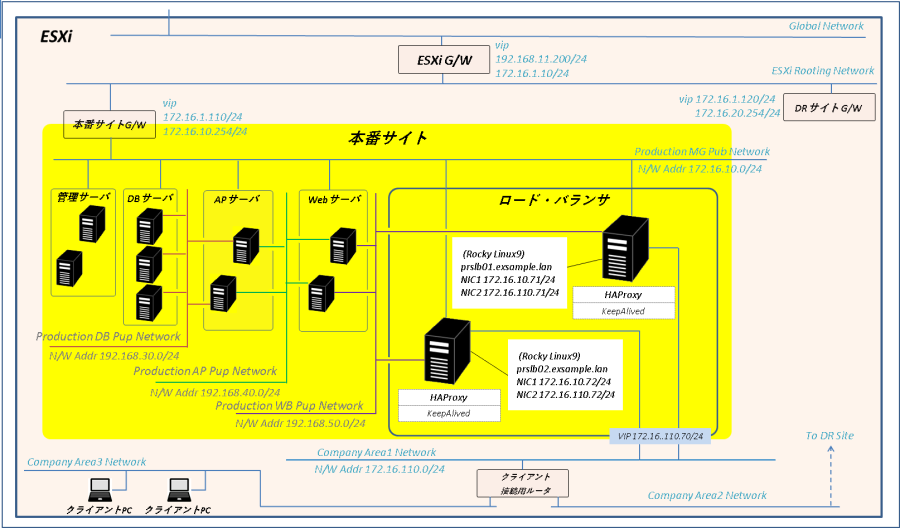
ロード・バランサは本番サイトで唯一外部のクライアントと通信が可能なネットワーク(本番サイト接続用ネットワーク)に接続します。
クライアントからのリクエストを受け取るのは各ロード・バランサの実アドレスではなくKeepalivedによって管理された仮想IPアドレス(VIP)です。このVIPは通常、ロード・バランサ#1で保持、ロード・バランサ#1障害時にバックアップのロード・バランサ#2に移動します。
VIPで受け取った クライアントPCからのリクエストはHAProxyが本番サイト内のWebサーバに振り分けます。HAProxyはリバース・プロキシと透過的プロキシ(単なる負荷分散)の両方をサポートしていますが本番サイトはリバース・プロキシ構成です。
クライアント – ロード・バランサ – Webサーバ間の通信はひとまずHTTPオンリーです。システムの構築がひと段落したところでロード・バランサの設定にHTTPS/HTTP変換を追加しようと思います。
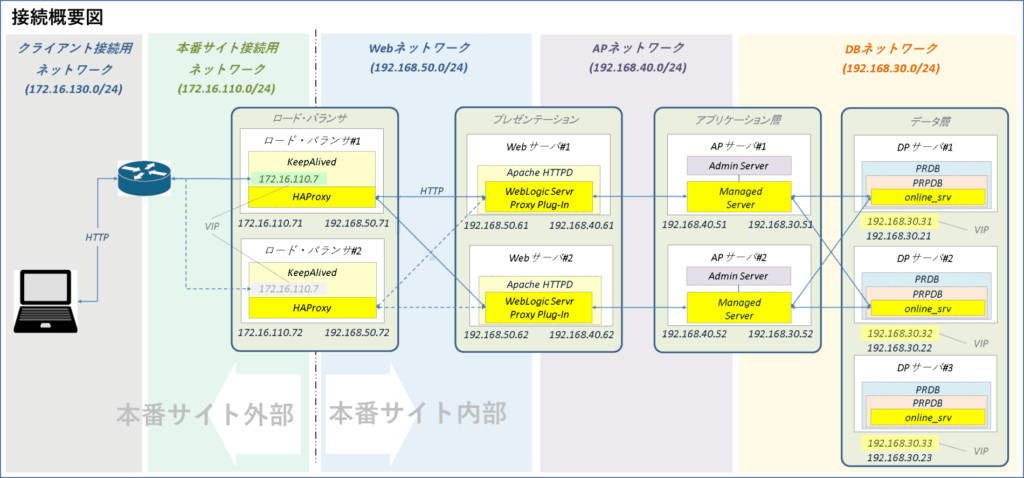
ネットワーク
ロード・バランサのネットワーク構成は以下の通りです。
【ネットワーク構成】
| ネットワーク | ポートグループ | N/Wアドレス | IPアドレス | 用途 |
| 本番サイト管理用ネットワーク | Production MG Pub Network | 172.16.10.0/24 | ロード・バランサ#1:172.16.10.71 ロード・バランサ#2:172.16.10.72 | サーバ管理用 |
| 本番サイト接続用ネットワーク | Company Area1 Network | 172.16.110.0/24 | ロード・バランサ#1:172.16.110.71 ロード・バランサ#2:172.16.110.72 ロードバランサ(VIP):172.16.110.70 | 業務サービス用 |
| Webネットワーク | Production WB Pub Network | 192.168.50.0/24 | ロード・バランサ#1:192.168.50.71 ロード・バランサ#2:192.168.50.72 | Webサーバとの通信用 |
ハードウェア
ロード・バランサはあまりリソースを食わないので割り当ては低めに設定します。
【ロード・バランサ 割り当てリソース】
| 設定項目 | 本番APサーバ設定値 |
| CPU | 2 |
| メモリ(RAM) | 2 GiB |
| SWAP | 4 GiB |
| OS用ローカル・ディスク | 100 GB |
ソフトウェア
HAProxy、keepalivedともRocky Linux のインストール・メディアに含まれているパッケージを使用します。Rocky Linux v9.5の場合、HAProxyのバージョンは 2.4.22、Keeplinuxdのバージョンはv2.2.8となっています。
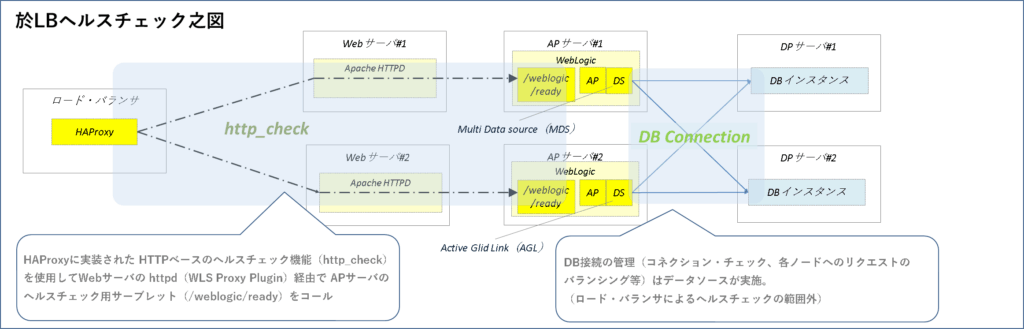
ヘルスチェック
ロード・バランサによる経路のヘルスチェックにはHAProxyに実装されたHTTPベースのヘルスチェック機能、http_checkを使用します。 http_checkがWebサーバ経由でAPサーバのWebLogicインスタンスにデプロイされたヘルスチェック用サーブレット(/weblogic/ready)をコール、ステータス200(正常)が返されればその経路はOKの状態です。もし200以外のステータスが返された場合、HAProxyはその経路へのリクエストの振り分けを停止します。
ファイアウォール
ここまで構築してきた本番サイトの各サーバは基本的にファイアウォールのPublicゾーンでネットワーク・インターフェースを管理しています。
唯一の例外はDBサーバのインターコネクトとして使っているネットワーク・インターフェースです。DBサーバ間の通信だけで使用していること、オール・スルーの通信が必要なことからこのネットワーク・インターフェースだけセキュリティゆるゆるのTrustedゾーンに置いています。
まあシステム内のサーバとやり取りする分にはPublicだろうがTrustedだろうがどのゾーンでネットワーク・インターフェースを管理しようとあまり問題ないのですが、ロード・バランサの場合はシステム外部のクライアントPCと通信しなくちゃならなりません。実装しているネットワーク・インターフェースをPublicゾーンで一纏めに管理するのはセキュリティ上、あまりよろしくない。
そこで本番サイト管理用ネットワークに接続されたロード・バランサのネットワーク・インターフェースはDMZゾーンに分離して必要最低限のアクセスのみ許可をするようにゾーンの設定を変更します。
ロード・バランサ構築
サーバ初期構築
仮想マシン作成
ロード・バランサとして使用する2台の仮想マシンを作成します。
【仮想マシン構成】
| 設定項目 | 設定値 |
| 仮想マシン名 | prslb01、prslb02 |
| CPU | 2 |
| Memory | 2 GB |
| Hard Disk 1 | 100 GB |
| Disk Provisioning | Thin provisioned |
| Network adapter 1 | ポートグループ「Production MG Pub Network」 |
| CD/DVD Media | <データストア・アップロード・ディレクトリ>/Rocky-9.5-x86_64-dvd.isoo |
OSインストール
作成した仮想マシンにOS(Rocky Linux v9.5)をインストールします。各ロード・バランサのホスト名及びIPアドレスは以下の通りです。
【ホスト名/IPアドレス一覧】
| ロードバランサ#1 | ロードバランサ#2 | |
| ホスト名 | prslb01.exsample.lan | prslb02.exsample.lan |
| IPアドレス | 172.16.10.71 | 172.16.10.72 |
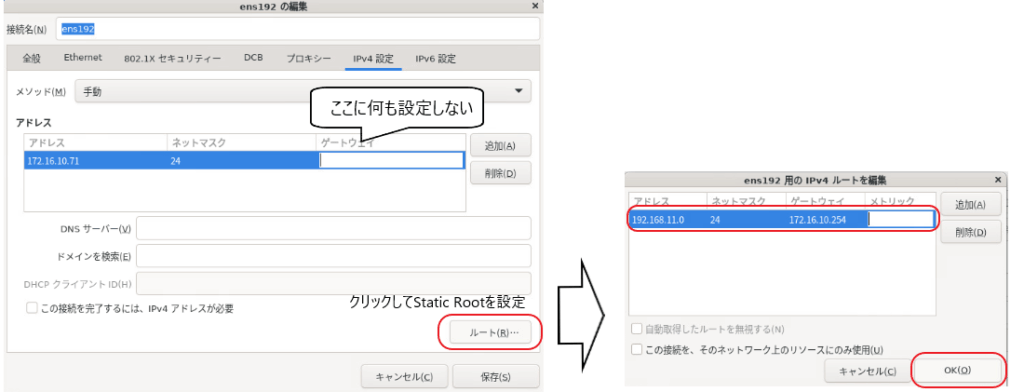
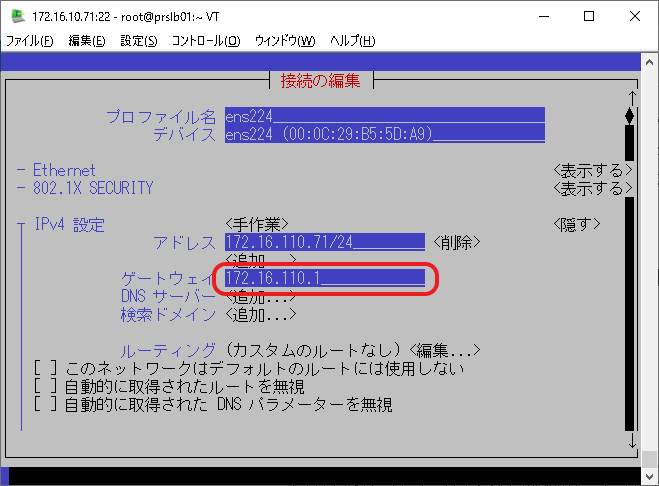
他のサーバとは異なりロード・バランサのデフォルト・ゲートウェイは本番サイト・ゲートウェイ(172.16.10.254)ではなくクライアント接続用ルータ(172.16.110.1)です。
OSインストール時は本番サイト管理用ネットワークのネットワーク アダプタしか存在しない(その他のネットワーク アダプタはOSインストール後に追加する)のでデフォルト・ゲートウェイを設定せずESXi外部のネットワークに対するスタティック・ルートを設定します。
サーバ初期構築
Rocky Linux 9の初期構築手順を実施します。
事前準備
ネットワーク・アダプタ追加
本番サイト接続用ネットワークのアダプタ、Webネットワークのアダプタを仮想マシンに追加します。各アダプタに割り当てるポートグループとIPアドレスは以下の通りです。
【仮想マシン・追加ネットワーク・アダプタ】
| ネットワーク・アダプタ | ポートグループ |
| ネットワーク アダプタ 2 | Company Area1 Network |
| ネットワーク アダプタ 3 | Production WB Pub Network |
【N/Wインターフェース・IPアドレス設定】
| デバイス名 | ロード・バランサ#1(prslb01) | ロード・バランサ#2(prslb02) |
| ens224 | 172.16.110.71/24 | 172.16.110.72/24 |
| ens256 | 192.168.50.71/24 | 192.168.50.72/24 |
なお、ネットワーク アダプタ 2のネットワーク・インターフェース(ens224)のゲートウェイにはクライアント接続用ルータのIPアドレス(172.16.110.1)を設定します。
マウント・シェル準備
ロード・バランサ#1でWebサーバから各種マウント・シェルを取得してロード・バランサ#2に配布ます。
【prslb01 / rootユーザで実行】
-----------------------------------------------------------------------------
# DVDマウント用シェルをWebサーバ#1から取得
scp 172.16.10.61:/usr/local/bin/dvdmount /usr/local/bin/
# メディア用NFS共有ディレクトリのマウント関連シェルをWebサーバ#1から取得
scp 172.16.10.61:/usr/local/bin/md*mount /usr/local/bin/
# 取得したマウント関連シェルをロード・バランサ#2に展開
scp /usr/local/bin/* 172.16.10.72:/usr/local/bin/
DVDリポジトリ用repoファイル作成
DVDリポジトリ用のrepoファイルを作成します。
【prslb01、prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# /etc/yum.repos.d/に移動
cd /etc/yum.repos.d/
# 既存repoファイル退避
mkdir -p bkup;mv *.* bkup/;ls
# DVDリポジトリ用repoファイル作成
cat > RLNX-DVD.repo <<EOF
[ISO-Base]
name=RockyLinux-DVD-Base
baseurl=file:///mnt/cdrom/BaseOS
gpgcheck=0
enabled=1
[ISO-Appstrem]
name=RockyLinux-DVD-AppStream
baseurl=file:///mnt/cdrom/AppStream
gpgcheck=0
enabled=1
EOF
# DVDリポジトリ用repoファイル確認
cat RLNX-DVD.repo
dnf repolist
hosts設定
ロード・バランサ#1で/etc/hostsファイルを編集してロード・バランサ#2に転送します。
【prslb01 / rootユーザで実行】
-----------------------------------------------------------------------------
# /etc/hostsファイル編集
vi /etc/hosts
# /etc/hostsファイルをロード・バランサ#2に転送
scp /etc/hosts 172.16.10.72:/etc/
/etc/hosts(クリックで表示)
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.10.10 prsmg00.exsample.lan prsmg00
172.16.10.11 prsmg01.exsample.lan prsmg01
172.16.10.12 prsmg02.exsample.lan prsmg02
172.16.10.21 prsdb01-mgt.exsample.lan prsdb01-mgt
172.16.10.22 prsdb02-mgt.exsample.lan prsdb02-mgt
172.16.10.23 prsdb03-mgt.exsample.lan prsdb03-mgt
172.16.10.51 prsap01-mgt.exsample.lan prsap01-mgt
172.16.10.52 prsap02-mgt.exsample.lan prsap02-mgt
172.16.10.61 prswb01-mgt.exsample.lan prswb01-mgt
172.16.10.62 prswb02-mgt.exsample.lan prswb02-mgt
172.16.10.71 prslb01-mgt.exsample.lan prslb01-mgt
172.16.10.72 prslb02-mgt.exsample.lan prslb02-mgt
192.168.50.61 prswb01.exsample.lan prswb01
192.168.50.62 prswb02.exsample.lan prswb02
192.168.50.70 prsweb.exsample.lan prsweb
192.168.50.70 prslb00-wbs.exsample.lan prslb00-wbs
192.168.50.71 prslb01-wbs.exsample.lan prslb01-wbs
192.168.50.72 prslb02-wbs.exsample.lan prslb02-wbs
172.16.110.70 prslb00.exsample.lan prslb00 prsite.exsample.lan prsite
172.16.110.71 prslb01.exsample.lan prslb01
172.16.110.72 prslb02.exsample.lan prslb02
ファイアウォール設定
各ロード・バランサのファイアウォールを以下のように設定します。
【ファイアウォール設定内容】
| ゾーン | 設定内容 |
| DMZ | ・forwardを削除 ・サービスからsshを削除 ・プロトコルにvrrpを追加 ・VIP(172.16.110.70)宛のhhtpポート(80/tcp)へのアクセスを許可 ・VIP(172.16.110.70)宛のhhtpsポート(443/tcp)へのアクセスを許可 |
| Public | ・本番サイト接続用N/Wインターフェース(ens224)をDMZゾーンに移動 ・ESXi外部ネットワークに対してHAProxyの統計確認用ポート(8404/tcp)へのアクセス許可 |
【prslb01、prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# 現在のPublic及びDMZゾーンの状態を確認
firewall-cmd --list-all
firewall-cmd --list-all --zone=dmz
# I/F間のフォワーディングは行わないのでDMZゾーンのフォワーディングを削除
firewall-cmd --remove-forward --zone=dmz --permanent
# DMZゾーンのサービスからsshを削除
firewall-cmd --remove-service=ssh --zone=dmz --permanent
# DMZゾーンのプロトコルにVRRPを追加
firewall-cmd --add-protocol=vrrp --zone=dmz --permanent
# 本番サイト接続用N/Wインターフェース(ens224)をDMZゾーンに移動
firewall-cmd --change-interface=ens224 --zone=dmz --permanent
# VIP宛httpリクエストを許可
firewall-cmd --add-rich-rule='rule family="ipv4" destination address="172.16.110.70" port port="80" protocol="tcp" accept' --zone=dmz --permanent
# VIP宛httpsリクエストを許可
firewall-cmd --add-rich-rule='rule family="ipv4" destination address="172.16.110.70" port port="443" protocol="tcp" accept' --zone=dmz --permanent
# HAProxy実行時の統計確認用
firewall-cmd --add-rich-rule='rule family="ipv4" source address="192.168.11.0/24" port port="8404" protocol="tcp" accept' --permanent
# firewalldの設定をリロード
firewall-cmd --reload
# 設定がPublic及びDMZゾーンに反映されていることを確認
firewall-cmd --list-all
firewall-cmd --list-all --zone=dmz
DB、アプリケーション・サーバ、Webサーバ起動
DB(Oracle RAC)、アプリケーション・サーバ(WebLogic)、Webサーバ(Apache httpd)が停止している場合は起動します。
DB(Oracle RAC)起動
各DBサーバのCRSを起動します。
【prsdb01、prsdb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# CRS起動(prsdb01→prsdb02の順に1台ずつCRSを起動)
/opt/app/21.0.0/grid/bin/crsctl start crs -wait
DBサーバ#1でDBインスタンス、PDB、online_srvサービスの起動状況を確認して停止している場合は起動します。
【prsdb01で実行】
-----------------------------------------------------------------------------
# oracleユーザにスイッチ
su - oracle
# DBの起動状況を確認
srvctl status database -db prdb
# DBが停止している場合は起動
srvctl start database -db prdb
# PDBの起動状況を確認
srvctl status pdb -db prdb -pdb prpdb
# PDBが停止している場合は起動
srvctl start pdb -db prdb -pdb prpdb
# online_srvサービスの起動状況を確認
srvctl status service -db prdb -service online_srv
# online_srvサービスが停止している場合は起動
srvctl start service -db prdb -service online_srv
アプリケーション・サーバ(WebLogic)起動
APサーバのWebLogicインスタンスを起動します。
【prsap01、prsap02で実行】
-----------------------------------------------------------------------------
# oracleユーザにスイッチ
su - oracle
# Admin Server起動
/opt/app/oracle/bin/startWebLogic_prs.sh
# Managed Server起動
/opt/app/oracle/bin/startManagedWebLogic_prs.sh
Webサーバ(Apache httpd)起動
WebサーバのApache httpdを起動します。
【prswb01、prswb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# Apache httpd起動
systemctl start httpd
# httpd動作確認
curl "http://`uname -n`"
→ "This is <ホスト名>."が返されることを確認
# httpd - WebLogic連携確認
curl "http://`uname -n`/ConnCheck/DBAliveCheck"
→ "OK"が返されることを確認
WLS Proxy Plug-in設定追加(Webサーバ側作業)
WebサーバのhttpdにWebLogicヘルスチェック用のWLS Proxy Plug-in定義を追加します。
【prswb01、prswb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# WebLogicヘルスチェックのWLS Proxy Plug-in定義追加
cat > /etc/httpd/conf.d/wlhealth.conf <<EOF
<Location /weblogic/ready>
ConnectTimeoutSecs 1
ConnectRetrySecs 1
SetHandler weblogic-handler
WebLogicHost `hostname -s | sed 's/prswb/prsap/g'`
WebLogicPort 7003
</Location>
EOF
# httpd再起動
systemctl restart httpd
# WebLogicヘルスチェックへのリダイレクト確認
curl -I "http://`uname -n`/weblogic/ready"
→ "HTTP/1.1 200 OK"が返されればOK
ip_nonlocal_bindパラメータ設定
KeepAlivedが管理するVIPは常にどちらか一方のロード・バランサが保持します。HAProxyのfrontendでVIPのバインドを設定した場合、VIPを持たないBACKUP側のロードバランサはHAPoxyの起動に失敗します。
VIPを持たないロードバランサの起動失敗例(クリックで表示)
[root@prslb01 ~]# systemctl start haproxy.service
Job for haproxy.service failed because the control process exited with error code.
See "systemctl status haproxy.service" and "journalctl -xeu haproxy.service" for details.
[root@prslb01 ~]#
[root@prslb01 ~]# journalctl -xeu haproxy.service
…
10月 05 15:30:30 prslb01.exsample.lan haproxy[6225]: [ALERT] (6225) : Starting frontend main: cannot bind socket (Cannot assign requested address) [172.16.110.70:80]
…
10月 05 15:30:30 prslb01.exsample.lan haproxy[6225]: [ALERT] (6225) : Starting frontend main: cannot bind socket (Cannot assign requested address) [172.16.110.70:443]
…
10月 05 15:30:30 prslb01.exsample.lan haproxy[6225]: [ALERT] (6225) : [/usr/sbin/haproxy.main()] Some protocols failed to start their listeners! Exiting.
10月 05 15:30:30 prslb01.exsample.lan systemd[1]: haproxy.service: Main process exited, code=exited, status=1/FAILURE
Subject: Unit process exited
Defined-By: systemd
Support: https://wiki.rockylinux.org/rocky/support
An ExecStart= process belonging to unit haproxy.service has exited.
The process' exit code is 'exited' and its exit status is 1.
10月 05 15:30:30 prslb01.exsample.lan systemd[1]: haproxy.service: Failed with result 'exit-code'.
Subject: Unit failed
Defined-By: systemd
Support: https://wiki.rockylinux.org/rocky/support
The unit haproxy.service has entered the 'failed' state with result 'exit-code'.
10月 05 15:30:30 prslb01.exsample.lan systemd[1]: Failed to start HAProxy Load Balancer.
Subject: A start job for unit haproxy.service has failed
Defined-By: systemd
Support: https://wiki.rockylinux.org/rocky/support
A start job for unit haproxy.service has finished with a failure.
The job identifier is 2350 and the job result is failed.
[root@prslb01 ~]#
これを回避するためにカーネル・パラメータに「net.ipv4.ip_nonlocal_bind = 1」を設定してローカルでないIPアドレスへのIP転送およびバインディングを有効化します。。
【prslb01、prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# 現在のip_nonlocal_bindパラメータの設定を確認
sysctl -a | grep ip_nonlocal_bind
→ もしnet.ipv4.ip_nonlocal_bindに1が設定されていれば以下の作業は不要。0なら後続のパラメータ変更実施
# カーネル・パラメータ設定ファイル作成
cat > /etc/sysctl.d/99-nonlocal_bind.conf <<EOF
net.ipv4.ip_nonlocal_bind = 1
EOF
# カーネル・パラメータ設定ファイルの内容をカーネルに反映
sysctl --system
# 反映後のip_nonlocal_bindパラメータの設定を確認
sysctl -a | grep ip_nonlocal_bind
→ net.ipv4.ip_nonlocal_bind = 1となっていることを確認
クライアントPC作成
以下の設定でクライアントPCの仮想マシンを作成します。
【仮想マシン構成】
| 設定項目 | 設定値 |
| 仮想マシン名 | clientpc |
| CPU | 1 |
| Memory | 2 GB |
| Hard Disk 1 | 100 GB |
| Disk Provisioning | Thin provisioned |
| Network adapter 1 | ポートグループ「Global Network」 |
| Network adapter 2 | ポートグループ「Company Area3 Network」 |
| CD/DVD Media | <データストア・アップロード・ディレクトリ>/Rocky-9.5-x86_64-dvd.isoo |
仮想マシンを作成したらRocky Linux v9.5をインストールします。インストール設定は以下の通りです。
【インストール先】
| マウント・ポイント | サイズ |
| /boot | 1024 MiB |
| swap | 4096 MiB |
| /var | 30 GiB |
| / | 指定しない(残りの領域すべてを割り当て) |
【ネットワークとホスト名(N)】
| ホスト名 | clientpc |
| タブ | 設定項目 | ens192 | ens224 |
| IPv4設定 | メソッド | 手動 | 手動 |
| IPv4設定 | IPアドレス | 192.168.11.210 | 172.16.130.11 |
| IPv4設定 | ネットマスク | 24 | 24 |
| IPv4設定 | ゲートウェイ | – | 172.16.130.1 |
| IPv4設定 | DNSサーバ | – | – |
| IPv4設定 | ドメイン検索 | – | – |
| IPv6設定 | メソッド | 無効 | 無効 |
【ソフトウェアの選択(S)】
| 選択ソフトウェア (計 1541パッケージ) | デバッグツール ネットワークファイルシステムクライアント パフォーマンスツール 開発ツール グラフィカル管理ツール システムツール |
HAProxy構築
HAProxy、KeepAlivedインストール
各ロード・バランサにHAProxy及びKeepAlivedをインストールします。
【prslb01、prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# DVDマウント
dvdmount
# HAProxy、KeepAlivedインストール
dnf -y install haproxy keepalived
ログ出力設定
各ロード・バランサのrsyslogdに対してHAProxyとKeepalivedの出力設定を追加します。
【prslb01、prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# リスニングソケット用ディレクトリ、ログディレクトリを作成
mkdir /var/lib/haproxy/dev
mkdir /var/log/haproxy
mkdir /var/log/keepalived
# HAProxy用のrsyslog定義を作成
cat > /etc/rsyslog.d/haproxy.conf <<EOF
\$AddUnixListenSocket /var/lib/haproxy/dev/log
\$template haproxy,"%timegenerated:1:10:date-rfc3339% %timegenerated:12:23:date-rfc3339% %msg%\n
local2.* -/var/log/haproxy/haproxy.log;haproxy
EOF
# Kepalived用のrsyslog定義を作成
echo "local0.* /var/log/keepalived/keepalived.log" > /etc/rsyslog.d/keepalived.conf
# Keepalivedのsyslogファシリティを0 に設定
sed -i 's|KEEPALIVED_OPTIONS="-D"|KEEPALIVED_OPTIONS="-D -d -S 0"|g' /etc/sysconfig/keepalived
# rsyslogd.confの構文チェック
rsyslogd -N 1
# 構文チェックで問題がなければrsyslogd再起動
systemctl restart rsyslog.service
HAProxyをインストールすると/etc/logrotate.dにログ・ローテーション定義が作られます。Keepalivedはパッケージをインストールしてもログ・ローテーション定義が作成されないのでHAProxyの定義に相乗りしてログ・ローテーションを設定します。
HAProxyのログ・ローテーション定義を開き、HAProxyログのパスを修正してKeepalivedログを追記します。
【prslb01、prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# HAProxyのログ・ローテーション定義を編集
vi /etc/logrotate.d/haproxy
---------------------------------
【編集内容】
---------------------------------
(編集前)
/var/log/haproxy.log
{
daily
rotate 10
↓
(編集後)
/var/log/haproxy/haproxy.log 1行目 haproxy.logのファイルパスを修正
/var/log/keepalived/keepalived.log 2行目にKeepalivedのログ・ファイルを挿入
{
daily
rotate 30 ローテーションの世代数を10 → 30に変更
RHEL系OSはデフォルトのログ・ローテーション・サイクルが週次に設定されていのでlogrotate.confを編集して日次に変更します。
【prslb01、prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# ログ・ローテーション定義ファイルを編集
vi /etc/logrotate.conf
---------------------------------
【編集内容】
---------------------------------
(編集前)
# rotate log files weekly
weekly
# keep 4 weeks worth of backlogs
rotate 4
↓
(編集後)
# rotate log files weekly
#weekly 6行目"weekly "をコメントアウト
daily 次行に"daily"を設定
# keep 4 weeks worth of backlogs
#rotate 4 9行目"rotate 4"をコメントアウト
rotate 30 次行に"rotate 30"を設定
HAProxy設定
haproxy.cfgを編集してHAProxyの設定を行います。haproxy.cfgはロード・バランサ#1とロード・バランサ#2で共通の内容なのでロード・バランサ#1で編集してからロード・バランサ#2に転送します。
【prslb01 / rootユーザで実行】
-----------------------------------------------------------------------------
# /etc/haproxy/haproxy.cfgを編集
vi /etc/haproxy/haproxy.cfg
→ 編集内容は下記「/etc/haproxy/haproxy.cfg」参照(緑文字部分が編集箇所)
# /etc/haproxy/haproxy.cfgをロード・バランサ#2に転送
scp /etc/haproxy/haproxy.cfg prslb02-mgt:/etc/haproxy/
/etc/haproxy/haproxy.cfg(クリックで表示・緑文字部分が編集箇所)
#---------------------------------------------------------------------
# Example configuration for a possible web application. See the
# full configuration options online.
#
# https://www.haproxy.org/download/1.8/doc/configuration.txt
#
#---------------------------------------------------------------------
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
# log 127.0.0.1 local2
log /dev/log local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
# utilize system-wide crypto-policies
ssl-default-bind-ciphers PROFILE=SYSTEM
ssl-default-server-ciphers PROFILE=SYSTEM
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend main
# frontend IP address:port(HTTP)
bind 172.16.110.70:80
bind 172.16.110.71:80
bind 172.16.110.72:80
# frontend IP address:port(HTTPS)
bind 172.16.110.70:443
bind 172.16.110.71:443
bind 172.16.110.72:443
default_backend app_backend
# HAProxy Monitoring
frontend stats
mode http
bind 172.16.10.71:8404
bind 172.16.10.72:8404
stats enable
stats refresh 10s
stats uri /stats
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend app_backend
# Distribute to another server when server connection fails.
option redispatch
retries 1
# Various timeout settings
# (timeout server sets the timeout for responses from the backend.
# The actual setting should be adjusted according to your system requirements.)
timeout connect 3s
timeout server 1m
timeout client 10s
timeout check 2s
# Health check
option httpchk
http-check send meth GET uri /weblogic/ready
http-check expect status 200
# backend servers
# (Three failed health checks: Down, two successful checks: Up)
server prswb01 192.168.50.61:80 check fall 3 inter 2000 rise 2
server prswb02 192.168.50.62:80 check fall 3 inter 2000 rise 2
# Setting up a sorry page when all servers are down
acl no_srv nbsrv(app_backend) eq 0
http-request return status 200 content-type "text/html" file /etc/haproxy/sorry.html if no_srv
2026/4/1:app_backendのtimeout serverを5sからデフォルトの1mに修正。理由については修正履歴を参照
ロード・バランサ#1でバックエンド・サーバがすべてダウンしたときに表示するSorryページを作成してロード・バランサ#2に転送します。
【prslb01 / rootユーザで実行】
-----------------------------------------------------------------------------
# sprryページ作成
cat > /etc/haproxy/sorry.html <<EOF
<html>
<body>
<h1>Sorry, we're currently undergoing maintenance.</h1>
</body>
</html>
# Sorryページをロード・バランサ#2に転送
scp /etc/haproxy/sorry.html prslb02-mgt:/etc/haproxy/
動作検証
リクエスト転送と振り分け
HAProxyを起動してリクエスト転送と振り分けを検証します。
各Webサーバには“This is <Webサーバのホスト名>.”を返すindex.htmlが仕込んであります。フロントエンドのIPアドレスにはロード・バランサ自身のIPアドレスも設定してあるので、バックエンドへのリクエスト転送と振り分けに問題がなければロード・バランサのIPアドレス宛にcurlでリクエストを飛ばすと2台のWebサーバのindex.htmlが交互に返されてくるはずです。
で、実際にやってみた結果がこれ。
【ロード・バランサ#1 確認結果】
-----------------------------------------------------------------------------
[root@prslb01 ~]# systemctl start haproxy.service
[root@prslb01 ~]#
[root@prslb01 ~]# curl "http://`uname -n`"
This is prswb01.
[root@prslb01 ~]# curl "http://`uname -n`"
This is prswb02.
[root@prslb01 ~]# curl "http://`uname -n`"
This is prswb01.
[root@prslb01 ~]# curl "http://`uname -n`"
This is prswb02.
[root@prslb01 ~]# curl "http://`uname -n`"
This is prswb01.
[root@prslb01 ~]# curl "http://`uname -n`"
This is prswb02.
[root@prslb01 ~]#
Webサーバ名を入れ替えながらindex.htmlの応答が返されています。この結果はロード・バランサ#1のものだけですがロード・バランサ#2でも同じような結果でした。
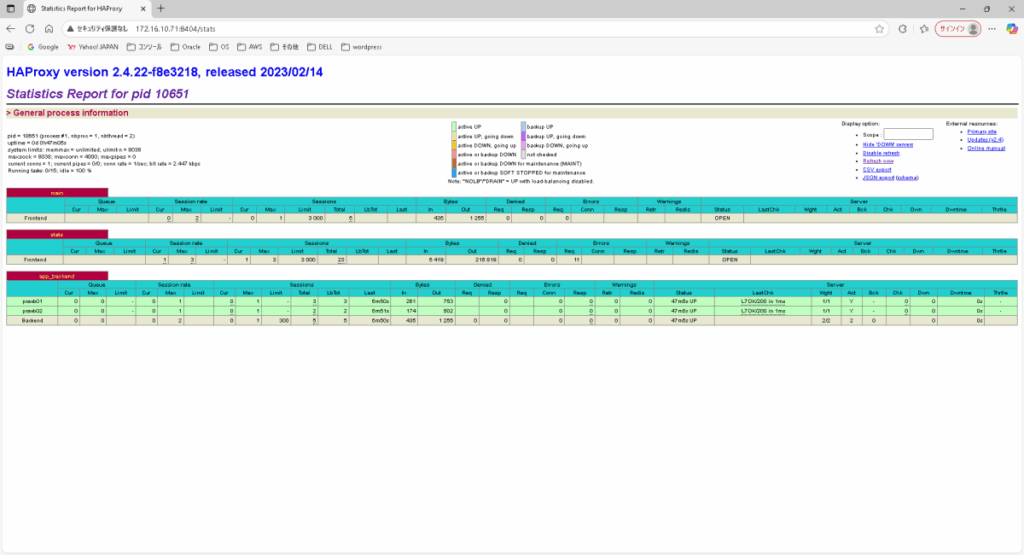
HAProxy実行統計取得
PCのブラウザでロード・バランサの8404ポートにアクセスしてHAProxyの実行統計が表示されることを確認します。
| 接続先ロードバランサ | URL |
| ロード:バランサ#1 | http://172.16.10.71:8404/stats |
| ロード:バランサ#2 | http://172.16.10.72:8404/stats |
こちらがロード・バランサ#1の実行統計ページ。haproxy.cfgの実行統計定義やネットワーク設定に問題なければこのページが表示されます。
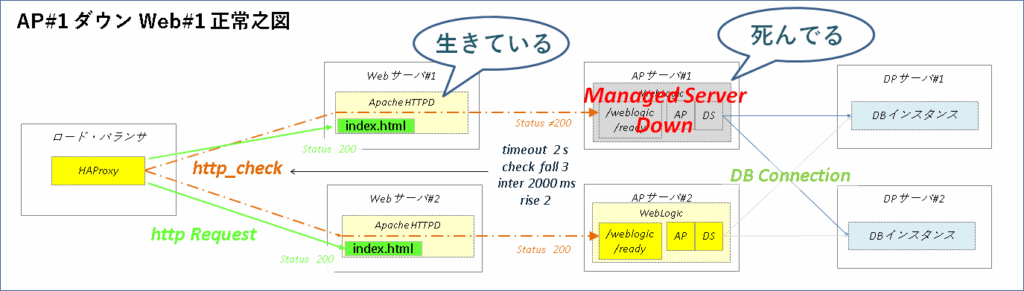
ヘルスチェック・エラーによる振り分け停止
APサーバ#1のManaged Serverを強制終了してHAProxyのヘルスチェック・エラーによる振り分け停止を確認します。
APサーバ#1のManaged Serverを強制終了してもロードバランサとの経路上にあるWebサーバ#1は生きていますがヘルスチェックの設定(check fall 3 inter 2000 rise 2)に問題がなければ3回目のチェック・エラーでWebサーバ#1への振り分けが停止します。
ついでにAPサーバ障害発生から振り分け停止までの経過時間も確認したいのでロード・バランサ#1でHTTPリクエストを連投しながらManaged Serverを強制終了してみます。
【ロード・バランサ#1 確認結果】
-----------------------------------------------------------------------------
[root@prslb01 ~]# for ((i=1;i<1000;i++));do echo $(printf "%03d" ${i})" "$(date +"%H:%M:%S")" "$(curl -s "http://`uname -n`") 2>/dev/null ;sleep 1;done
001 23:08:20 This is prswb02.
002 23:08:21 This is prswb01. ← ここでManaged Server強制終了
003 23:08:22 This is prswb02.
004 23:08:23 This is prswb01.
005 23:08:24 This is prswb02.
006 23:08:25 This is prswb01.
007 23:08:26 This is prswb02.
008 23:08:27 This is prswb01.
009 23:08:28 This is prswb02.
010 23:08:29 This is prswb01.
011 23:08:30 This is prswb02.
012 23:08:31 This is prswb01.
013 23:08:32 This is prswb02.
014 23:08:33 This is prswb02. ← ここからWebサーバ01(prswb01)への振り分け停止
015 23:08:34 This is prswb02.
016 23:08:35 This is prswb02.
^C
[root@prslb01 ~]# view /var/log/haproxy/haproxy.log
(前略)
2025-10-10 23:08:33.387 Server app_backend/prswb01 is DOWN, reason: Layer7 timeout, check duration: 2002ms. 1 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue.
(後略)
【APサーバ#1 Managed Server強制終了】
-----------------------------------------------------------------------------
[oracle@prsap01 ~]$ ps -ef | grep java | grep "\-Dweblogic\.Name=prs_ap01" | awk '{print $2}'
37820
[oracle@prsap01 ~]$ kill -9 37820;date
2025年 10月 10日 金曜日 23:08:21 JST ← Managed Serverを強制終了した時間
[oracle@prsap01 ~]$
実行結果を見ると 23:08:33 からリクエストがWebサーバ#1に振られなくなっています。その後はWebサーバ#2だけ応答しているのでヘルスチェック・エラーによる振り分け停止はOKです。
APサーバ障害発生から振り分け停止までの経過時間は12秒かかっています。HAProxyのヘルスチェック設定は”check fall 3 inter 2000”なので4~6秒程度で振り分け停止となりそうなところ、実際はその倍です。まあ、業務影響があるほどの長さではないのでヘルスチェックのパラメータ調整はせずこのままの設定で行きます。
実はこれ、調べたらhttpdのWLS Proxy Pluginが止まっているManaged Serverに接続リトライしていて応答が遅く(3秒)、HAProxy側でヘルスチェックが毎回タイムアウト(2秒)していたのが原因でした。
試しにWLS Proxy PluginではなくApacheのmod_proxyにhttpdからManaged Serverへのリダイレクトを任せたら約5秒で振り分け停止しました。
正直、WLS Proxy PluginはWebLogic側でクラスタを組んでいないとあまり意味がない、というかApacheのmod_proxyを使った方がいいんじゃないかと思います。
まあ、今回はこうした製品仕様の確認自体が目的のひとつであり、またWebLogic側は後々(できれば)クラスタ化してみようというのもあったのでこのままWLS Proxy Pluginで行こうと思います。
【Webサーバ#1 リダイレクト設定変更】
—————————————————————————–
[root@prswb01 ~]# cat /etc/httpd/conf.d/wlhealth.conf
ProxyPass /weblogic/ready http://prsap01:7003/weblogic/ready
ProxyPassReverse /weblogic/ready http://prsap01:7003/weblogic/ready
[root@prswb01 ~]#
【APサーバ#1 Managed Server強制終了】
—————————————————————————–
[oracle@prsap01 ~]$ ps -ef | grep java | grep “\-Dweblogic\.Name=prs_ap01” | awk ‘{print $2}’
23273
[oracle@prsap01 ~]$ kill -9 23273;date
2025年 10月 12日 日曜日 00:11:00 JST
[oracle@prsap01 ~]$
【ロード・バランサ#1 確認結果】
—————————————————————————–
[root@prslb01 ~]# for ((i=1;i<1000;i++));do echo $(printf “%03d” ${i})” “$(date +”%H:%M:%S”)” “$(curl -s “http://`uname -n`”) 2>/dev/null ;sleep 1;done
001 00:10:57 This is prswb02.
002 00:10:58 This is prswb01.
003 00:10:59 This is prswb02.
004 00:11:00 This is prswb01. ← ここでManaged Server強制終了
005 00:11:01 This is prswb02.
006 00:11:02 This is prswb01.
007 00:11:03 This is prswb02.
008 00:11:04 This is prswb01.
009 00:11:05 This is prswb02. ← ここからWebサーバ01(prswb01)への振り分け停止
010 00:11:06 This is prswb02.
011 00:11:07 This is prswb02.
^C
[root@prslb01 ~]# view /var/log/haproxy/haproxy.log
(前略)
2025-10-12 00:11:05.401 Server app_backend/prswb01 is DOWN, reason: Layer7 wrong status, code: 503, info: “Service Unavailable”, check duration: 1ms. 1 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue.
(後略)
バックエンド・サーバ全滅によるSorryページの表示
バックエンド・サーバ全滅時のHTTPリクエストに対してSorryページが返されることを確認します。
Webサーバ#1の経路は既に(APサーバ#1のManaged Server停止で)振り分けが停止してるので、このままHTTPリクエストを連投しながらWebサーバ#2のhtpdを停止します。
【prswb02 httpd停止】
-----------------------------------------------------------------------------
[root@prswb02 ~]# systemctl stop httpd.service;date
2025年 10月 12日 日曜日 02:00:31 JST
[root@prswb02 ~]#
【ロード・バランサ#1 確認結果】
-----------------------------------------------------------------------------
[root@prslb01 ~]# for ((i=1;i<1000;i++));do echo $(printf "%03d" ${i})" "$(date +"%H:%M:%S")" "$(curl -s "http://`uname -n`") 2>/dev/null ;sleep 1;done
001 02:00:28 This is prswb02.
002 02:00:29 This is prswb02.
003 02:00:30 <html><body><h1>503 Service Unavailable</h1> No server is available to handle this request. </body></html>
004 02:00:32 <html><body><h1>503 Service Unavailable</h1> No server is available to handle this request. </body></html>
005 02:00:34 <html><body><h1>503 Service Unavailable</h1> No server is available to handle this request. </body></html>
Message from syslogd@prslb01 at Oct 12 02:00:36 ...
haproxy[21376]: backend app_backend has no server available!
006 02:00:36 <html> <body> <h1>Sorry, we're currently undergoing maintenance.</h1> </body> </html>
007 02:00:37 <html> <body> <h1>Sorry, we're currently undergoing maintenance.</h1> </body> </html>
008 02:00:38 <html> <body> <h1>Sorry, we're currently undergoing maintenance.</h1> </body> </html>
009 02:00:39 <html> <body> <h1>Sorry, we're currently undergoing maintenance.</h1> </body> </html>
^C
[root@prslb01 ~]#
※緑字の部分はsyslogdによるアラートです。ロード・バランサに接続しているすべてのターミナルにバックエンド・サーバ全滅の通知が届きます。
問題なくSorryページが返されています。httpdの停止からSorryページが返されるまでが約5秒なのはこれも想定通り。WLS Proxy Pluginもこれぐらいのレスポンスで応答してほしいところです。
HAProxyの動作確認は以上です。動作確認で停止したManaged Server(APサーバ#1)とhttpd(Webサーバ#2)を起動してすべての経路を正常な状態に復旧します。
【prsap01 / oracleユーザで実行】
-----------------------------------------------------------------------------
# Managed Server起動
/opt/app/oracle/bin/startManagedWebLogic_prs.sh
【prswb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# httpd起動
systemctl start httpd.service
Keepalived構築
HAProxyの構築が終わったら次はKeepalivedです。KeepalivedはMASTERとBACKUPで設定が少し異なるので先にMASTER側を設定してからそれをベースにBACKUP側を設定します。
MASTER側設定
ロード・バランサ”#1でkeepalived.confを編集します。
【prslb01 / rootユーザで実行】
-----------------------------------------------------------------------------
# /etc/keepalived/keepalived.conf編集
vi /etc/keepalived/keepalived.conf
→ 編集内容は下記「/etc/keepalived/keepalived.conf」参照
/etc/keepalived/keepalived.conf(クリックで表示)
! Configuration File for keepalived
global_defs {
router_id LB_01
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
enable_script_security
script_user root
}
vrrp_script chk_haproxy {
script "/usr/bin/killall -0 haproxy"
interval 2
fall 2
rise 2
timeout 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens224
virtual_router_id 1
priority 100
nopreempt
advert_int 1
authentication {
auth_type PASS
auth_pass passw123
}
virtual_ipaddress {
172.16.110.70/24 dev ens224
}
track_interface {
ens224
ens256
}
track_script {
chk_haproxy
}
}
【keepalived.confの補足】
————————————————————————————————-
global_defs
・router_id: ロードバランサの識別名
・enable_script_security:Keepalived がスクリプトを実行する際、スクリプトの所有者やパーミッションをチェック
vrrp_script chk_haproxy:
追跡監視用の vrrp_script(chk_haproxy)を定義。HAProxyがダウンしていればエラー
vrrp_instance VI_1
・state BACKUP:
ロード・バランサのMASTERとBACKUPを設定(LB#1、LB#2ともBACKUPならpriorityの高いノードがMASTERに昇格)
・nopreempt:
state BACKUPとnopreemptを設定している場合、別のノードがMASTERとして稼働している状況で自ノードとMASTERのpriorityの逆転が生じても自ノードのMASTER昇格を抑止。平たくいえば自動フェイルバック抑止
・advert_int:アドバタイズパケットの送信間隔
・track_interface:追跡するインターフェースを指定
・track_script:Keepalivedが vrrp_script 定義に従って一定の間隔で実行するプログラム
Keepalivedを起動してネットワーク・インターフェース ens224にVIPが追加されていることを確認します。
【prslb01 / rootユーザで実行】
-----------------------------------------------------------------------------
# KeepAlived起動
systemctl start keepalived.service
# ens224のVIPを確認
ip addr show dev ens224
→ secondaryに172.16.110.70/24が設定されていること
# VIPへのping疎通を確認
ping -c 2 172.16.110.70
# VIP→Webサーバへのリクエスト転送を確認
curl "http://172.16.110.70"
→ "This is prswb01."または"This is prswb02."が返されること
# VIP→Webサーバ→APサーバへのリクエスト転送を確認
curl "http://172.16.110.70/ConnCheck/DBAliveCheck"
→ "OK"が返されること
-----------------------------------------------------------------------------
【ロード・バランサ#1 ens224・VIP確認】
-----------------------------------------------------------------------------
[root@prslb01 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224
valid_lft forever preferred_lft forever
[root@prslb01 ~]#
クライアントPCからVIPと各ロード・バランサの実IPに向けてping疎通及びHTTPリクエストによる接続確認を試行します。
【clientpc / rootユーザで実行】
-----------------------------------------------------------------------------
# hostsエントリ追加
cat >> /etc/hosts <<EOF
172.16.110.70 prsite.exsample.lan prsite
172.16.110.71 prslb01.exsample.lan prslb01
172.16.110.71 prslb02.exsample.lan prslb02
EOF
# ping疎通確認
ping -c 2 prsite
ping -c 2 prslb01
ping -c 2 prslb02
# ロード・バランサの実IPアドレスへのファイアウォール接続拒否確認
curl "http://prslb01"
→ ホストへの経路がありません」と返されること
curl "http://prslb02"
→ ホストへの経路がありません」と返されること
# ロード・バランサのVIPへの接続確認
curl "http://prsite"
→ "This is prswb01."または"This is prswb02."が返されること
curl "http://prsite/ConnCheck/DBAliveCheck"
→ "OK"が返されること
クライアントPCからの接続確認に問題がなければロード・バランサ#1のKeepalivedとHAProxyを停止、ロード・バランサ#2にkeepalived.confを転送します。
【prslb01 / rootユーザで実行】
-----------------------------------------------------------------------------
# KeepAlivedを停止
systemctl stop keepalived.service
# HAProxyを停止
systemctl stop haproxy.service
# keepalived.confをロード・バランサ#2に転送
scp /etc/keepalived/keepalived.conf prslb02-mgt:/etc/keepalived/
BACKUP側設定
ロード・バランサ#2のkeepalived.confを以下のように編集します。
【prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# keepalived.confを編集
vi /etc/keepalived/keepalived.conf
---------------------------------
【編集内容】
---------------------------------
(編集前)
priority 100
nopreempt
advert_int 1
↓
(編集後)
priority 50 28行目 priorityを100 → 50に変更
nopreempt29行目を削除
advert_int 1
【編集内容の補足】
nopreemptを MASTERとBACKUPの両方に設定してしまうとtrack_script等、MASTER側のpriority減少によるフェイルオーバーが機能しなくなります。
Keepalivedを起動してネットワーク・インターフェース ens224へのVIP追加、VIP宛のping疎通とHTTPリクエスト転送に問題がないことを確認します。
【prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# KeepAlived起動
systemctl start keepalived.service
# ens224のVIPを確認
ip addr show dev ens224
→ secondaryに172.16.110.70/24が設定されていること
# VIPへのping疎通を確認
ping -c 2 172.16.110.70
# VIPでWebサーバへのリクエスト転送を確認(Webサーバ宛)
curl "http://172.16.110.70"
# VIPでWebサーバへのリクエスト転送を確認(WebLogic宛)
curl "http://172.16.110.70/ConnCheck/DBAliveCheck"
-----------------------------------------------------------------------------
【ロード・バランサ#2 ens224・VIP確認 実行例】
-----------------------------------------------------------------------------
[root@prslb02 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:73:39:48 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.72/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224
valid_lft forever preferred_lft forever
[root@prslb02 ~]#
クライアントPCからVIP宛にHTTPリクエストを飛ばして応答に問題がないことを確認します。
【clientpc / rootユーザで実行】
-----------------------------------------------------------------------------
# ロード・バランサのVIPへの接続確認
curl "http://prsite"
→ "This is prswb01."または"This is prswb02."が返されること
curl "http://prsite/ConnCheck/DBAliveCheck"
→ "OK"が返されること
ロード・バランサ#2でKeepalivedとHAProxyを一旦停止します。
【prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# KeepAlivedを停止
systemctl stop keepalived.service
# HAProxyを停止
systemctl stop haproxy.service
動作検証
VRRP構成
2台のロード・バランサでKeepalivedを起動してVRRPの構成に問題がないこと(MASTER側のみVIPを保持していること)を確認します。
ロード・バランサ#1 → ロード・バランサ#2の順番でHAProxyとKeepalivedを起動します。
【ロード・バランサ#1 HAProxy、Keepalived 起動】
-----------------------------------------------------------------------------
[root@prslb01 ~]# systemctl is-active haproxy.service keepalived.service
inactive
inactive
[root@prslb01 ~]# systemctl start haproxy.service
[root@prslb01 ~]# systemctl start keepalived.service
[root@prslb01 ~]#
[root@prslb01 ~]# systemctl is-active haproxy.service keepalived.service
active
active
[root@prslb01 ~]#
【ロード・バランサ#2 HAProxy、Keepalived 起動】
-----------------------------------------------------------------------------
[root@prslb02 ~]# systemctl is-active haproxy.service keepalived.service
inactive
inactive
[root@prslb02 ~]# systemctl start haproxy.service
[root@prslb02 ~]# systemctl start keepalived.service
[root@prslb02 ~]#
[root@prslb02 ~]# systemctl is-active haproxy.service keepalived.service
active
active
[root@prslb02 ~]#
各ロード・バランサのHAProxyとKeepalivedを起動したらネットワーク・インターフェース (ens224)を確認します。
【ロード・バランサ#1 VIP確認】
-----------------------------------------------------------------------------
[root@prslb01 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224
valid_lft forever preferred_lft forever
[root@prslb01 ~]#
【ロード・バランサ#2 VIP確認】
-----------------------------------------------------------------------------
[root@prslb02 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:73:39:48 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.72/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
[root@prslb02 ~]#
ロード・バランサ#1(MASTER側)のネットワーク・インターフェースのみにVIPが設定されいます。VRRPの構成は問題ありません。
ちなみにうまくVRRPが構成できていないとこんなことが起きたりします。
→ 各ロード・バランサでVIPが競合
(firewalldでvrrpを遮断して各ロード・バランサでkeepalivedを起動)
—————————————————————————–
[root@prslb01 ~]# systemctl start keepalived.service
[root@prslb01 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224 ← LB#1でVIP保持
valid_lft forever preferred_lft forever
[root@prslb01 ~]#
[root@prslb02 ~]# systemctl start keepalived.service
[root@prslb02 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:73:39:48 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.72/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224 ← LB#2でもVIP保持
valid_lft forever preferred_lft forever
[root@prslb02 ~]#
Keepalived停止
ロード・バランサ#1(MASTER)のKeepalivedを停止してVIPのフェイルオーバーと、これにともなうサービス影響を確認します。
HAProxyの振り分け停止確認と同じようにロード・バランサのVIPに向けてHTTPリクエストを1秒間隔で飛ばしながらKeepalivedを停止します。HTTPリクエスト送信元はロードバランサ自身ではなく今度はクライアントPCです。また、Webサーバのindex.htmlではなくDB生死確認用のサーブレット(DBAliveCheck)をコールします。
【クライアントPCからHTTPリクエスト実行結果】
-----------------------------------------------------------------------------
[root@clientpc ~]# for ((i=1;i<1000;i++));do echo $(printf "%03d" ${i})" "$(date +"%H:%M:%S")" "$(curl -s "http://prsite/ConnCheck/DBAliveCheck") 2>/dev/null ;sleep 1;done
001 14:48:52 OK
002 14:48:53 OK
003 14:48:54 OK
004 14:48:55 OK ← このへんでLB#1のKeepalived停止
005 14:48:57 OK
006 14:48:58 OK
007 14:48:59 OK
008 14:49:00 OK
^C
[root@clientpc ~]#
【ロード・バランサ#1 確認結果】
-----------------------------------------------------------------------------
[root@prslb01 ~]# systemctl stop keepalived.service;date
2025年 10月 12日 日曜日 14:48:55 JST
[root@prslb01 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
[root@prslb01 ~]#
【ロード・バランサ#2 確認結果】
-----------------------------------------------------------------------------
[root@prslb02 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:73:39:48 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.72/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224
valid_lft forever preferred_lft forever
[root@prslb02 ~]#
VIPがロード・バランサ#2(BACKUP)に移動してます。クライアントからのHTTPリクエストが途切れたのは 14:48:56 の1秒だけなのでフェイルオーバーによるサービス影響はほとんどありません。
フェイルオーバーがうまくいったのでロード・バランサ#1のKeepalivedを起動しても自動フェイルバックしないことを確認します。
【ロード・バランサ#1 確認結果】
-----------------------------------------------------------------------------
[root@prslb01 ~]# systemctl start keepalived.service
[root@prslb01 ~]# sleep 5;ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
[root@prslb01 ~]#
ロード・バランサ#1にVIPが戻っていません。自動フェイルバックの抑止もOKです。
次はロード・バランサ#2のKeepalivedを再起動して手動によるフェイルバックが可能なことを確認します。
【ロード・バランサ#2 確認結果】
-----------------------------------------------------------------------------
[root@prslb02 ~]# systemctl restart keepalived.service
[root@prslb02 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:73:39:48 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.72/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
[root@prslb02 ~]#
【ロード・バランサ#1 確認結果】
-----------------------------------------------------------------------------
[root@prslb01 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224
valid_lft forever preferred_lft forever
[root@prslb01 ~]#
ロード・バランサ#1にVIPが戻っていますね。手動フェイルバックに確認はOKです。
HAProxy停止(track_script設定確認)
KeepalivedはHAProxyと連動してリクエストを処理するためtrack_scriptでHAProxyプロセスを追跡(監視)しています。track_scriptは2秒間隔で監視を行っており、プロセスダウンを2回検知するとpriorityを減少させてフェイルオーバーを実行します。
クライアントPCからHTTPリクエストを飛ばしながらロード・バランサ#1のHAProxyを停止することによってtrack_scriptが正しく機能することを確認します。
【クライアントPC・HTTPリクエスト実行結果】
-----------------------------------------------------------------------------
[root@clientpc ~]# for ((i=1;i<1000;i++));do echo $(printf "%03d" ${i})" "$(date +"%H:%M:%S")" "$(curl -s "http://prsite/ConnCheck/DBAliveCheck") 2>/dev/null ;sleep 1;done
001 18:00:56 OK
002 18:00:57 OK
003 18:00:58 OK ← ここでHAProxy停止
004 18:00:59
005 18:01:00
006 18:01:01 OK
007 18:01:03 OK
008 18:01:04 OK
009 18:01:05 OK
^C
[root@clientpc ~]#
【ロード・バランサ#1 確認結果】
-----------------------------------------------------------------------------
[root@prslb01 ~]# systemctl stop haproxy.service;date
2025年 10月 14日 火曜日 18:00:58 JST
[root@prslb01 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
[root@prslb01 ~]#
【ロード・バランサ#2 確認結果】
-----------------------------------------------------------------------------
[root@prslb02 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:73:39:48 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.72/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224
valid_lft forever preferred_lft forever
[root@prslb02 ~]#
HAProxy停止直後にリクエストが2回失敗したもののフェイルオーバーによって3秒後には回復しています。track_scriptは2秒間隔のチェックが2回失敗したらフェイルオーバーとなる設定です。プロセスダウンからフェイルオーバーまでの見積時間は2~4秒、実際の結果は3秒なのでtrack_scriptは正常に機能しています。
続けてロード・バランサ#2のtrack_scriptも確認します。ロード・バランサ#1でHAPRoxyを起動してからロード・バランサ#2のHAProxyを停止します。
【ロード・バランサ#1 HAProxy起動】
-----------------------------------------------------------------------------
[root@prslb01 ~]# systemctl start haproxy.service
[root@prslb01 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
[root@prslb01 ~]#
【ロード・バランサ#2 確認結果】
-----------------------------------------------------------------------------
[root@prslb02 ~]# systemctl stop haproxy.service;sleep 3;ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:73:39:48 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.72/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
[root@prslb02 ~]#
(ロード・バランサ#1でVIPを確認してからロード・バランサ#2のHAProxyを起動)
[root@prslb02 ~]# systemctl start haproxy.service
[root@prslb02 ~]#
【ロード・バランサ#1 確認結果】
-----------------------------------------------------------------------------
[root@prslb01 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224
valid_lft forever preferred_lft forever
[root@prslb01 ~]#
ロード・バランサ#1にVIPが戻っているのでロード・バランサ#2のtrack_scriptもOKです。
N/Wインタフェース障害(track_interface設定確認)
Keepalivedのvrrp_instanceにはフロントエンド及びバックエンドのネットワーク・インターフェース監視を設定しています。
この監視を担っているtrack_interfaceはどうやらカーネルがデバイス異常と認識しないとネットワーク・インターフェース障害と判定しないらしく、例えばnmcliでネットワーク・インターフェースを停止してもフェイルオーバーとはなりません。そこでESXiコンソールからネットワーク アダプタ接続を解除してtrack_interfaceが正常に機能しているかどうかを確認します。
なお、フロントエンドのネットワーク・インターフェース(ens224)はvrrp_instanceそのものに組み込まれているのでtrack_interfaceの判定に関わりなくダウンすれば即フェイルオーバーです。なので確認はバックエンドのネットワーク・インターフェース(ens256)を対象に実施します。
クライアントPCからロードバランサのVIPに向けて1秒間隔でHTTPリクエストを飛ばしながら…
【クライアントPC・HTTPリクエスト実行結果】
-----------------------------------------------------------------------------
[root@clientpc ~]# for ((i=1;i<1000;i++));do echo $(printf "%03d" ${i})" "$(date +"%H:%M:%S")" "$(curl -s "http://prsite/ConnCheck/DBAliveCheck") 2>/dev/null ;sleep 1;done
001 18:08:00 OK
002 18:08:01 OK
ESXiコンソールでロード・バランサ#1のネットワーク アダプタ3(Webネットワーク用アダプタ)の接続をぶちっ!
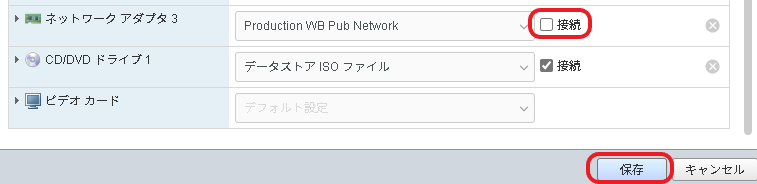
※タイミングによってはESXi側でアダプタの接続解除を拒否されるかもしれません。したらばリトライ!
【クライアントPC・HTTPリクエスト実行結果】
-----------------------------------------------------------------------------
[root@clientpc ~]# for ((i=1;i<1000;i++));do echo $(printf "%03d" ${i})" "$(date +"%H:%M:%S")" "$(curl -s "http://prsite/ConnCheck/DBAliveCheck") 2>/dev/null ;sleep 1;done
001 18:08:00 OK
002 18:08:01 OK
003 18:08:02 OK
004 18:08:03 OK
005 18:08:04 OK ← ここでWebネットワーク用のアダプタをぶち!
006 18:08:06 OK
007 18:08:07 OK
008 18:08:08 OK
009 18:08:09 OK
010 18:08:10 OK
011 18:08:11 OK
012 18:08:12 OK
013 18:08:13 OK
014 18:08:14 OK
015 18:08:15 OK
016 18:08:16 OK
^C
[root@clientpc ~]#
【ロード・バランサ#1 確認結果】
-----------------------------------------------------------------------------
[root@prslb01 ~]#
Message from syslogd@prslb01 at Oct 14 18:08:15 ...
haproxy[7884]: backend app_backend has no server available!
[root@prslb01 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
[root@prslb01 ~]# grep ens256 /var/log/messages | tail -2
Oct 14 18:08:04 prslb01 kernel: vmxnet3 0000:1b:00.0 ens256: NIC Link is Down
Oct 14 18:08:04 prslb01 Keepalived_vrrp[7532]: Netlink reports ens256 down
[root@prslb01 ~]#
[root@prslb01 ~]# tail -5 /var/log/keepalived/keepalived.log
Oct 14 18:05:12 prslb01 Keepalived_vrrp[7532]: Sending gratuitous ARP on ens224 for 172.16.110.70
Oct 14 18:08:04 prslb01 Keepalived_vrrp[7532]: Netlink reports ens256 down
Oct 14 18:08:04 prslb01 Keepalived_vrrp[7532]: (VI_1) Entering FAULT STATE
Oct 14 18:08:04 prslb01 Keepalived_vrrp[7532]: (VI_1) sent 0 priority
Oct 14 18:08:04 prslb01 Keepalived_vrrp[7532]: (VI_1) removing VIPs.
[root@prslb01 ~]#
【ロード・バランサ#2 確認結果】
-----------------------------------------------------------------------------
[root@prslb02 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:73:39:48 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.72/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224
valid_lft forever preferred_lft forever
[root@prslb02 ~]#
keepalived.logを見ると ens256がダウンしたのは 18:08:04 です。直後にクライアントPCのHTTPリクエストが1回失敗したものの、2秒後には復旧しています。
ロード・バランサ#1がBACKUPに降格してもHAProxyは上がったままなので 18:08:15 にsyslogdからバックエンド・サーバ全滅のアラート通知が出されています。しかしこの時点でVIPはとっくにフェイルオーバーしているためサービスへの影響はまったくありません。ロード・バランサ#1の track_interfaceは正常に機能しています。
一通り確認したところでロード・バランサ#1のens256を元の状態に戻します。ESXiコンソールでネットワーク アダプタ3を接続しなおしてからens256をアクティベートします。
【ロード・バランサ#1 ens256復旧】
-----------------------------------------------------------------------------
[root@prslb01 ~]# nmcli connection up ens256
接続が正常にアクティベートされました (D-Bus アクティブパス: /org/freedesktop/NetworkManager/ActiveConnection/5)
[root@prslb01 ~]#
[root@prslb01 ~]# ping -c 1 192.168.50.71
PING 192.168.50.71 (192.168.50.71) 56(84) bytes of data.
64 バイト応答 送信元 192.168.50.71: icmp_seq=1 ttl=64 時間=0.075ミリ秒
--- 192.168.50.71 ping 統計 ---
送信パケット数 1, 受信パケット数 1, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.075/0.075/0.075/0.000 ms
[root@prslb01 ~]#
続けてロード・バランサ#2のtrack_interfaceです。
ESXiコンソールでロード・バランサ#2のネットワーク アダプタ3の接続を解除してからどちらのロード・バランサがVIPを保持しているかを確認します。
【ロード・バランサ#1 確認結果】
-----------------------------------------------------------------------------
[root@prslb01 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:b5:5d:a9 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.71/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
inet 172.16.110.70/24 scope global secondary ens224
valid_lft forever preferred_lft forever
[root@prslb01 ~]#
【ロード・バランサ#2 確認結果】
-----------------------------------------------------------------------------
[root@prslb02 ~]#
Message from syslogd@prslb02 at Oct 14 18:20:06 ...
haproxy[7370]: backend app_backend has no server available!
[root@prslb02 ~]# ip addr show dev ens224
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:73:39:48 brd ff:ff:ff:ff:ff:ff
altname enp19s0
inet 172.16.110.72/24 brd 172.16.110.255 scope global noprefixroute ens224
valid_lft forever preferred_lft forever
[root@prslb02 ~]#
VIPがロードバランサ#1に戻っているのでこちらもOKです。
ESXiコンソールでロード・バランサ#2のネットワーク アダプタ3を接続しなおしてからens256をアクティベートします。
【ロード・バランサ#2 ens256復旧】
※ESXiコンソールでネットワーク・アダプタ接続を戻してから実施
-----------------------------------------------------------------------------
[root@prslb02 ~]# nmcli connection up ens256
接続が正常にアクティベートされました (D-Bus アクティブパス: /org/freedesktop/NetworkManager/ActiveConnection/5)
[root@prslb02 ~]# ping -c 1 192.168.50.72
PING 192.168.50.72 (192.168.50.72) 56(84) bytes of data.
64 バイト応答 送信元 192.168.50.72: icmp_seq=1 ttl=64 時間=0.109ミリ秒
--- 192.168.50.72 ping 統計 ---
送信パケット数 1, 受信パケット数 1, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.109/0.109/0.109/0.000 ms
[root@prslb02 ~]#
ログ・ローテーション確認
手動でログ・ローテーションを実行してhaproxy.logとkeepalived.logの日付付きファイルが作成されてることを確認します。
【prslb01、prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# haproxy.logが出力されていることを確認
ls /var/log/haproxy/
# keepalived.logが出力されていることを確認
ls /var/log/keepalived/
# 手動でログ・ローテーションを実行
logrotate -fv /etc/logrotate.conf
# haproxy.logがローテーションされたことを確認
ls /var/log/haproxy/
# keepalived.logがローテーションされたことを確認
ls /var/log/keepalived/
サービス起動順序及び依存関係の設定
MASTER側のロードバランサでHAProxyがダウンしているとKeepalivedはVIPをフェイルオーバーします。なのでKeepalivedを起動するときは先にHAProxyを起動する必要があります。
毎回これを意識しながらKeepalivedを起動するのは微妙に面倒なので、systemdにKeepalivedとHAProxyの順序関係と依存関係を設定します。
各ロードバランサのKeepalivedとHAProxyを停止します。
【prslb01、prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# Keepalivedを停止
systemctl stop keepalived.service
# HAProxyを停止
systemctl stop haproxy.service
systemdのHAProxyユニットとKeepalivedユニットに設定ファイルを追加します。
【prslb01、prslb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# systemdのHAProxyユニットとKeepalivedユニットに追加設定用ディレクトリを作成
mkdir -p /etc/systemd/system/haproxy.service.d/
mkdir -p /etc/systemd/system/keepalived.service.d/
# HAProxy.serviceユニットの追加設定ファイルを作成
cat > /etc/systemd/system/haproxy.service.d/override.conf <<EOF
[Unit]
Before=keepalived.service
EOF
# keepalived.serviceユニットの追加設定ファイルを作成
cat > /etc/systemd/system/keepalived.service.d/override.conf <<EOF
[Unit]
After=haproxy.service
Wants=haproxy.service
[Service]
Restart=always
RestartSec=2
EOF
# 念のためデーモン・リロード
systemctl daemon-reload
Before、Afterで順序関係、Wantsで依存関係(弱い依存関係)を設定します。
【補足1】
Keepalivedの起動時にHAProxyが停止状態ならばsystemdはWantsの設定に従い先にHAProxyを自動起動します。ただし弱い依存関係なのでHAProxyを停止してもKeepalivedは起動したままです。
WantsではなくRequires(強い依存関係)を設定した場合はHAProxyの停止によってKeepalivedも停止します。ただしKeepalivedは正常停止ではなく強制停止であり、サービス状態はfailedとなってしまいます。まあHAProxyが停止すればKeepalivedの状態がどうであれ、どっちにしろフェイルオーバーですからね。ここはWantsで十分かと。
【補足2】
「MASTERのkeepalivedプロセスがクラッシュするとVIPが解放されず、MASTERに昇格したBACKUP側でも VIPを設定するので競合状態になる」的な話がいくつかのサイトに書かれています。ただ、実際にMASTER側の keepalivedを強制停止(prcess kill)してもVIPをつかんだままにはならないんですよねぇ…
ChatGptにMASTER側のVIPが解放される理由を聞いてもいくつか推測を挙げるだけで確定情報は不明なままでした。
おまじない的にExecStopPostでVIP解放を入れようかとも思ったんですがそれが機能するか試しようがないのでやめておきます。
【ChatGptの推測】
・KeepalivedはVIPを追加する際に ip addr add ではなく netlink ソケット経由でプロセス依存的に登録 しているかも
・RHEL9の keepalived.service は KillMode=control-group などの設定でプロセスグループ全体を管理。systemd のプロセス終了時に関連するネットワークリソースをクリーンアップしているかも
・NetworkManager が VRRPで追加された secondary IP を監視対象としているかも
Keepalivedを起動してHAProxyとの依存関係が正常に機能するかを確認します。
【prslb01、prslb02 / rootユーザで実行】
ロード・バランサ#1 → ロード・バランサ#2の順に実行
-----------------------------------------------------------------------------
# HAProxy、Keepalivedがどちらも停止していることを確認
systemctl is-active haproxy.service keepalived.service
→ "inactive inactive"が返されること
# keepalivedを起動
systemctl start keepalived.service
# HAProxy、Keepalivedとも起動したことを確認
systemctl is-active haproxy.service keepalived.service
→ "active active"が返されること
# HAProxyを停止
systemctl stop haproxy.service
# HAProxyを停止してもKeepalivedは起動したままなのを確認
systemctl is-active haproxy.service keepalived.service
→ "inactive active"が返されること
# HAProxyを起動
systemctl start haproxy.service
# HAProxy起動を確認
systemctl is-active haproxy.service
→ "active"が返されること
アクセスログの設定
アクセスログへのX-Forwarded-Forヘッダー出力確認(Webサーバ側)
HAProxyはX-Forwarded-Forヘッダーにリクエスト元であるクライアントPCのIPアドレスを埋め込んでWebサーバにリクエストを転送しています。また、Webサーバ(httpd)側はアクセスログにオリジナルの送信元(クライアントPCのIPアドレス)が表示される設定です。
各WebサーバのアクセスログにクライアントPCのIPアドレスが出力されていることを確認します。
【prswb01のアクセスログ】
-----------------------------------------------------------------------------
view /etc/httpd/logs/access_log
-------------------
192.168.50.71 - - [08/Oct/2025:21:56:54 +0900] "GET /weblogic/ready HTTP/1.0" 200 - "-" "-" "-"
192.168.50.71 - - [08/Oct/2025:21:56:56 +0900] "GET /weblogic/ready HTTP/1.0" 200 - "-" "-" "-"
192.168.50.71 - - [08/Oct/2025:21:56:58 +0900] "GET /ConnCheck/DBAliveCheck HTTP/1.1" 200 3 "-" "curl/7.76.1" "172.16.130.11"
192.168.50.71 - - [08/Oct/2025:21:56:58 +0900] "GET /weblogic/ready HTTP/1.0" 200 - "-" "-" "-"
192.168.50.71 - - [08/Oct/2025:21:57:00 +0900] "GET /weblogic/ready HTTP/1.0" 200 - "-" "-" "-"
192.168.50.71 - - [08/Oct/2025:21:57:00 +0900] "GET /ConnCheck/DBAliveCheck HTTP/1.1" 200 3 "-" "curl/7.76.1" "172.16.130.11"
192.168.50.71 - - [08/Oct/2025:21:57:02 +0900] "GET /weblogic/ready HTTP/1.0" 200 - "-" "-" "-"
192.168.50.71 - - [08/Oct/2025:21:57:02 +0900] "GET /ConnCheck/DBAliveCheck HTTP/1.1" 200 3 "-" "curl/7.76.1" "172.16.130.11"
@@
アクセスログへのヘルス・チェック出力除外
HAProxyは2秒に1回、一時間当たり1800回のヘルスチェックを実行します。BACKUPのロード・バランサでもHAProxyは常時起動状態なのでWebサーバのhttpdアクセスログには2台のロード・バランサから毎時3600回のヘルスチェックが記録されることになります。ヘルスチェックの記録をアクセスログに残してもあまり意味がないというかデメリットしかないのでこれを出力しないように設定します。
各Webサーバでwlhealth.confを開き、2行目に”SetEnv dontlog”を挿入します。
【prswb01、prswb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# ヘルスチェック用 WLS Proxy Plug-in定義編集
vi /etc/httpd/conf.d/wlhealth.conf
------------------------------------------------
【編集内容】
------------------------------------------------
(編集前)
<Location /weblogic/ready>
SetHandler weblogic-handler
↓
(編集後)
<Location /weblogic/ready>
SetEnv dontlog 2行目に"SetEnv dontlog"を挿入
SetHandler weblogic-handler
httpd.conf 224行目のアクセスログ設定に”env=!dontlog”を追加します。
【prswb01、prswb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# httpd.conf編集
vi /etc/httpd/conf/httpd.conf
------------------------------------------------
【編集内容】
------------------------------------------------
(編集前)
CustomLog "logs/access_log" combined
↓
(編集後)
CustomLog "logs/access_log" combined env=!dontlog 224行目に"env=!dontlog"を追加
httpdを再起動してアクセスログを確認します。ロード・バランサからのヘルスチェック出力が停止していればOKです。
【prswb01、prswb02 / rootユーザで実行】
-----------------------------------------------------------------------------
# httpd再起動
systemctl restart httpd.service
# アクセスログ確認
tail -f /etc/httpd/logs/access_log
→ "GET /weblogic/ready HTTP/1.0"が出力されなくなっていればOK
ロード・バランサの構築は一旦終了です。まだSSLまわりの設定が残っていますがこちらは投稿を分けて後日実行します。
で、次はOEM(Oracle Enterprise Manager)サーバを構築と思ったんですが、ようやく3層一通りそろったところでOEMの前にLB – Web – AP – DBの連携を少し試してみたいと思います。
サイト内リンク一覧
ネットワーク構築
管理用ネットワーク構築
仮想ルータ構築 1(構成概要、OSインストール)
仮想ルータ構築 2(vyos設定)
仮想ルータ構築 3(vyos・open-vm-tools)
本番サイト構築
本番サイト構築
本番サイト・管理サーバ構築
管理サーバ構築 1(chrony、named)
管理サーバ構築 2(Pacemaker、NFS Server)
本番サイト・DBサーバ構築
DBサーバ構築 1(全体構成)
DBサーバ構築 2(OSインストール、ストレージ(vmdisk)構成)
DBサーバ構築 3(Oracle RACインストール環境構築)
DBサーバ構築 4 (Grid Infra21cインストール)
DBサーバ構築 6(Oracle DB 2ノードRAC構築)
DBサーバ構築 7(Oracle RAC ノード追加)
本番サイト・APサーバ構築
APサーバ構築 1(Weblogicインストール)
APサーバ構築 2(WebLogicドメイン構築)
APサーバ構築3(JDBC接続)
APサーバ構築 4(DB接続確認用アプリ作成)
APサーバ構築 5(アプリ・デプロイ)
APサーバ構築 6(本番モード切替)
本番サイト・Webサーバ構築
Webサーバ構築(Apache + WLS Proxy Plug-in)
本番サイト・ロードバランサ構築
ロード・バランサ構築(HAPtroxy+Keepalived)
Web-AP-DB連携検証
Web-AP-DB連携検証1(Active GridLink)
Web-AP-DB連携検証2(DBノード障害)
参考情報
この投稿は以下のサイトを参考にさせていただきました。お礼申し上げます。
ロードバランサーの管理 | Red Hat Enterprise Linux | 7 | Red Hat Documentation

Ubuntu 22.04 LTS : Keepalived : 監視スクリプトで監視する : Server World
HAProxyのアクティブヘルスチェック機能を試してみる | SIOS Tech. Lab
多機能プロクシサーバー「HAProxy」のさまざまな設定例 | さくらのナレッジ
[高可用性] Keepalived(フェイルオーバー)とhaproxy(ロードバランシング)の組み合わせ – Viet Vang
【Linux】サービスの順序関係と依存関係 #systemd – Qiita
haproxyを利用して冗長化ロードバランサを構築する | SIOS Tech. Lab
メニュー
トップページ
自己紹介
問合せ(メール)
修正履歴
2026/4/1
「HAProxy設定」に記載したhaproxy.cfgの修正です。app_backendに設定した”timeout server”をtimeout serverを5s→1mに修正しました。
現在DB障害を伴うバックエンドの通信典型テストをやっていますがDBサーバ電源断、つまり正常な停止を伴わないDBサーバ・ダウン時にデータ・ソースが同ノードへ突っ込んだSQLリクエスト応答時間はAPサーバ#1(Multi Data Source)で最長32秒、APサーバ#2(Active GridLink)で最長53秒です。ややこしいことにダウン・ノードに振り分けられたSQLリクエストがすべてエラーとなるわけではなく、データ・ソースによって生存ノードに再投入されて時間はかかっても正常終了したりします(正常、異常の割合はノード・ダウン発生時のセッション使用状況による)。いずれにせよ”timeout server 5s”の設定では多少時間がかかっても正常終了するリクエストまで軒並みクライアントにエラーが返されてしまうためデフォルトの1mに戻します。
いやそもそも5sってどう見ても短すぎますよね。何を考えてこんな設定にしたんだろう…orz
2026/4/30
サイト内リンク一覧を追記
コメント