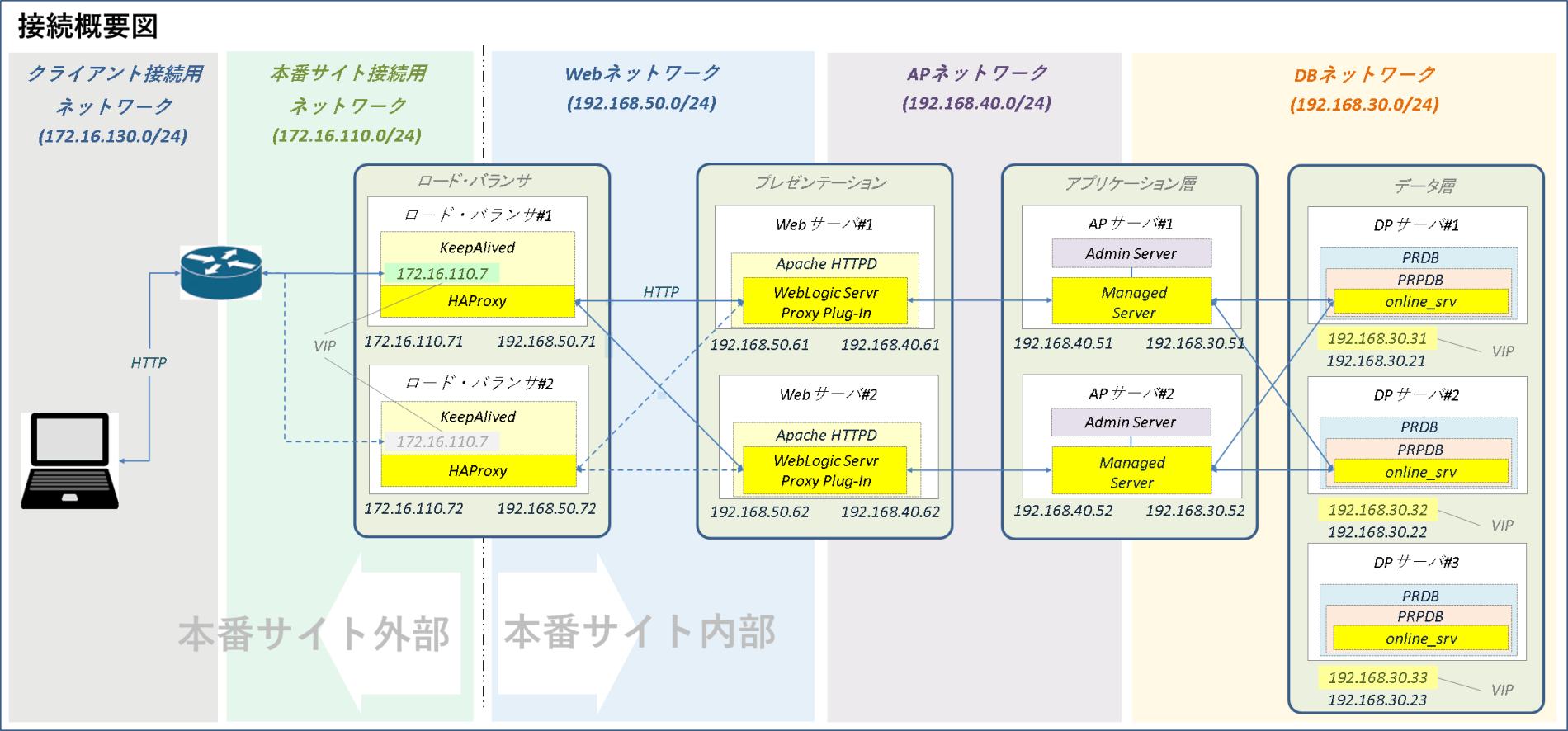
Web-AP-DB連携検証・概要
ロード・バランサ(LB)構築ではHTTPリクエスト振り分けやフロントエンド障害、バックエンド障害時のサービス影響について一通り検証てきたわけですが、いままで構築してきた過程でバックエンドの中身、Web-AP-DB間の連携については「接続できていること」程度の確認しかやってません。さすがにこれだけじゃあんまりなのでここらへんのところをここでもう少し細かく確認したいと思います。
Active GridLink(AGL)検証
実行時接続ロード・バランシング(RCLB)について
本番サイトのAPサーバ(WebLogic)に構成したデータソースはマルチ・データ・ソース(MDS)とActive GridLink(AGL)の2種類です。
APサーバ#1のMDSはDBノードへの接続固定かつ単純なラウンド・ロビンなので改めて確認することはありませんが、APサーバ#2のAGLがどんなバランシングをしているかについて私はこれまで同製品を扱ったことがないので正直よくわかりません。なので今回はAGLの機能検証です。
AGLはランタイム接続ロード・バランシング(RCLB)を実装しています。このRCLBの特徴をざっくりまとめると忙しそうなノードへのSQLリクエストの振り分けを減らして暇そうなノードに増やしたりセッションを移動したりしてくれる素敵な機能です。
Oracle WebLogic Server JDBCデータ・ソースの管理 14c (14.1.2.0.0)
実行時接続ロード・バランシング
GridLinkデータ・ソースで、XAや非XA環境でロード・バランシングが可能になります。GridLinkデータ・ソースは、ランタイム接続ロード・バランシング(RCLB)を使用して、データベースから発行されたOracle FANイベントに基づいて、Oracle RACインスタンスに接続を分配します。これにより、データ・ソースの構成が簡素化し、データ・ベースが、データベース・トポロジと独立して、GridLinkデータ・ソースを通じて接続のロード・バランシングを行うため、性能が向上します。
Universal Connection Pool開発者ガイド 21c
実行時接続ロード・バランシングの概要
Oracle Real Application Clusters環境では、接続は関連サービスを提供するインスタンスに属しています。すべてのインスタンスが等しく実行され、接続がキャッシュからランダムに取り出されるのが最も理想的です。しかし、あるインスタンスのパフォーマンスが他のインスタンスを上回る場合、接続をランダムに選択すると効率が悪くなります。実行時接続ロード・バランシング機能を使用すると、最適なパフォーマンスを提供するインスタンスに作業要求がルーティングされるため、作業を再配置する必要が最小限になります。
Oracle® Fusion Middleware ライセンス情報ユーザー・マニュアル
Oracle WebLogic Server GridLinkデータ・ソース(通称Active GridLink for RAC)の使用は、WebLogic SuiteまたはExalogic Elastic Cloud Softwareのライセンスの一部としてのみ使用できる権利です。
RCLBはDB側のロードバランシング・アドバイザから受け取った情報を元に作業分散の調整を行います。ロードバランシング・アドバイザはサービスに設定された目標(サービス目標)に従って各ノードに割り当てる作業量の配分を決定します。
このサービス目標について「Real Application Clusters管理およびデプロイメント・ガイド」では以下のように説明しています。
SERVICE_TIME: 応答時間に基づいて、作業要求をインスタンスに割り当てます。ロード・バランシング・アドバイザのデータは、サービスで完了した作業の経過時間およびサービスに対して使用可能な帯域幅に基づきます。SERVICE_TIMEの使用例としては、需要が変動するインターネット・ショッピングなどのワークロードがあります。
THROUGHPUT: スループットに基づいて、作業要求をインスタンスに割り当てます。ロード・バランシング・アドバイザのデータは、サービスで完了した作業の処理速度およびサービスに対して使用可能な帯域幅に基づきます。THROUGHPUTの使用例としては、前のジョブが完了してから次のジョブを開始するバッチ処理などのワークロードがあります。
ここには「サービスで完了した作業の経過時間」や「サービスで完了した作業の処理速度」という言葉が出てきますがそれが具体的にどの統計を指しているかは書かれていないので私には具体的なバランシングのイメージがつかめません。なので今回の検証ではそこのところを中心に確認していきたいと思います。
ちなみにAGLが接続する「online_srv」は現在サービス目標をTHROUGHPUTに設定しています。
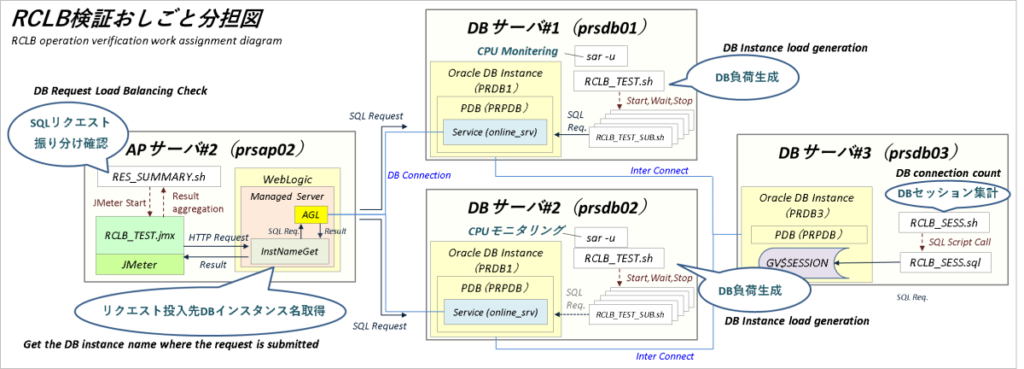
なお、検証ではAGL経由で連続してSQLリクエストを飛ばしたりノードに負荷を掛けたりいろいろやるのでそのためのツールが必要です。
ツールの詳細は事前準備のところで書くとして検証内容と検証環境の全体像はざっくりこんな感じで行こうと思います。
【ざっくり検証内容】
| 検証項目 | 検証内容 |
| セッションの動的分散(初期セッション) | Managed Server起動によってAGL-DB間で生成される初期セッションの挙動を確認 |
| セッションの動的分散(片ノード稼働上昇時) | AGLからSQLリクエストを流していない状態で片ノード稼働上昇時のセッションの挙動を確認 |
| SQLリクエスト・バランシング | AGLからDBにSQLリクエストを流してDB無風状態、片ノード稼働上昇、DB無風状態復帰それぞれの状況でSQLリクエスト及の振り分け及びセッションがどのようにバランシングされるかを確認 |
【ざっくり検証環境全体像】
※クリックで拡大
この投稿ではサービスに設定する目標の記述を”サービス目標”に統一しますが「Universal Connection Pool開発者ガイド」では”サービス目標”、「Real Application Clusters管理およびデプロイメント・ガイド」では”サービス・レベルの目標”、「Oracle WebLogic Server JDBCデータ・ソースの管理 14c (14.1.2.0.0)」では”サービスのGOAL”、srvctlの出力は”ランタイム・ロード・バランシング目標”とOracle側の表記がバラバラだったりします。
また、サービス目標とは別に「接続バランシング目標」というのもありましてこちらは作業の分散ではなく接続の分散を調整する目標ですが、困ったことにドキュメントによっては「作業」を「接続」と表現しているので読めば読むほど混乱します。そもそも「作業」にしたってSQLリクエストの振り分けだけを指すのか接続も含めているのかはっきりしない曖昧な書きっぷりですからね。こういうところはマジでなんとかしてくれないかな……
事前準備
Apache JMeter
実際の運用になるべく近い形でAGLによるSQLリクエストの振り分けを確認するにはパラレルかつ連続的にWebアプリをコールしなければなりません。その作業はApache JMeterにやってもらいます。
Apache JMeterのダウンロード・ページから最新バージョン(2025/11/5時点では5.6.3)のzip版をダウンロードしてAPサーバ#2に転送します。
Apache JMeter – Download Apache JMeter
JMeterの配置場所はここじゃなきゃダメという決まりは特にないので今回はoracleユーザのホーム・ディレクトリ(/home/oracle)にサブディレクトリを作成してそこでzipファイル展開します。
【prsap02 / oracleユーザで実行】
-----------------------------------------------------------------------------
# JMeter格納用ディレクトリ作成
mkdir /home/oracle/jmeter
(作成したディレクトリにJMeterのzipファイル格納)
# ZIP展開
cd /home/oracle/jmeter
unzip -q apache-jmeter-5.6.3.zip
APサーバの準備
JMeterテスト・プラン作成
JMeterのzipファイルを展開したらSQLリクエスト振り分け確認用テスト・プラン(シナリオ)を作成します。
本来はPCでテスト・プランを作成してテスト環境に持っていくのが正しいお作法なんでしょうがここは横着して直接APサーバ上でテスト・プランを作成します。
JMeterのテスト・プラン作成にはGUIを使用するのでAPサーバ#2でVNC Serverを起動してVNC Viewerでログインします。
【prsap02 / oracleユーザで実行】
-----------------------------------------------------------------------------
# VNC Server起動
vncserver :1
Viewer画面でターミナルを開き、以下のコマンドでJMeterを立ち上げます。
【prsap02 / VNC Viewer画面 / oracleユーザで実行】
-----------------------------------------------------------------------------
# JMeterのbinディレクトリに移動
cd /home/oracle/jmeter/apache-jmeter-5.6.3/bin
# 応答結果ファイル格納ディレクトリ作成
mkdir result
# JMeter起動
./jmeter
JMeterのGUI上でSQLリクエスト振り分け確認用テスト・プランを作成します。
テスト・プランが実行するHTTPリクエストの中身はManaged ServerにデプロイしてあるDBインスタンス名取得サーブレット(/ConnCheck/InstNameGet)です。これを複数のスレッドから一定間隔・回数無制限で実行します。
このテスト・プランは負荷生成が目的ではないのでスレッド数(並列度)と投入間隔はとりあえず緩めです。
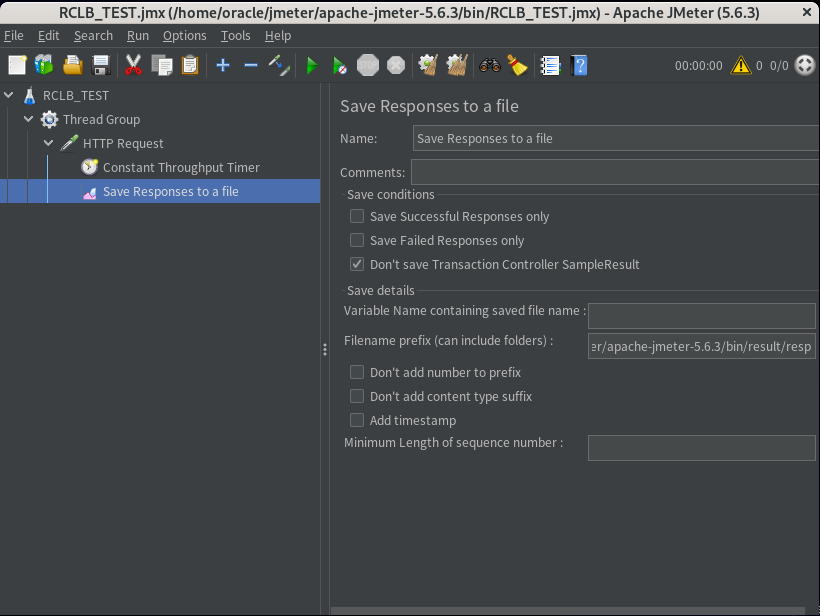
【JMeter・SQLリクエスト振り分け確認用テスト・プラン設定】
| 要素 | タイプ | 上位要素 | 設定値 |
| Test Plan | Test Plan | – | Name:RCLB_TEST |
| Thread Group | Thread(Users) | Test Plan | Number of Therads(users):40 Ramp-Up period(seconds):2 Loop Count: Infinite:チェック Same user on each Iteration:チェック Delay THread creation until needed:チェック |
| HTTP Request | Sampler | Thread Group | Server Name or IP:prsap02 Port Number:7003 HTTP Request:Get Path:/ConnCheck/InstNameGet |
| Constant Throughput Timer | Timer | HTTP Request | Target throughput(in sample per minute):30.0 Calculate Throughput based on:this thread only |
| Save Responses to a file | Listener | HTTP Request | Filename prefix(can include folders): /home/oracle/jmeter/apache-jmeter-5.6.3/bin/result |
| JMXファイル名 | – | – | RCLB_TEST.jmx |
RCLB_TEST.jmx(クリックで表示)
<?xml version="1.0" encoding="UTF-8"?>
<jmeterTestPlan version="1.2" properties="5.0" jmeter="5.6.3">
<hashTree>
<TestPlan guiclass="TestPlanGui" testclass="TestPlan" testname="RCLB_TEST">
<elementProp name="TestPlan.user_defined_variables" elementType="Arguments" guiclass="ArgumentsPanel" testclass="Arguments" testname="User Defined Variables">
<collectionProp name="Arguments.arguments"/>
</elementProp>
<boolProp name="TestPlan.functional_mode">false</boolProp>
<boolProp name="TestPlan.serialize_threadgroups">false</boolProp>
</TestPlan>
<hashTree>
<ThreadGroup guiclass="ThreadGroupGui" testclass="ThreadGroup" testname="Thread Group">
<boolProp name="ThreadGroup.delayedStart">true</boolProp>
<intProp name="ThreadGroup.num_threads">40</intProp>
<intProp name="ThreadGroup.ramp_time">2</intProp>
<boolProp name="ThreadGroup.same_user_on_next_iteration">true</boolProp>
<stringProp name="ThreadGroup.on_sample_error">continue</stringProp>
<elementProp name="ThreadGroup.main_controller" elementType="LoopController" guiclass="LoopControlPanel" testclass="LoopController" testname="Loop Controller">
<intProp name="LoopController.loops">-1</intProp>
<boolProp name="LoopController.continue_forever">false</boolProp>
</elementProp>
</ThreadGroup>
<hashTree>
<HTTPSamplerProxy guiclass="HttpTestSampleGui" testclass="HTTPSamplerProxy" testname="HTTP Request" enabled="true">
<stringProp name="HTTPSampler.domain">prsap02</stringProp>
<stringProp name="HTTPSampler.port">7003</stringProp>
<stringProp name="HTTPSampler.path">/ConnCheck/InstNameGet</stringProp>
<boolProp name="HTTPSampler.follow_redirects">true</boolProp>
<stringProp name="HTTPSampler.method">GET</stringProp>
<boolProp name="HTTPSampler.use_keepalive">true</boolProp>
<boolProp name="HTTPSampler.postBodyRaw">false</boolProp>
<elementProp name="HTTPsampler.Arguments" elementType="Arguments" guiclass="HTTPArgumentsPanel" testclass="Arguments" testname="User Defined Variables">
<collectionProp name="Arguments.arguments"/>
</elementProp>
</HTTPSamplerProxy>
<hashTree>
<ConstantThroughputTimer guiclass="TestBeanGUI" testclass="ConstantThroughputTimer" testname="Constant Throughput Timer" enabled="true">
<intProp name="calcMode">0</intProp>
<doubleProp>
<name>throughput</name>
<value>30.0</value>
<savedValue>0.0</savedValue>
</doubleProp>
</ConstantThroughputTimer>
<hashTree/>
<ResultSaver guiclass="ResultSaverGui" testclass="ResultSaver" testname="Save Responses to a file" enabled="true">
<stringProp name="FileSaver.filename">/home/oracle/jmeter/apache-jmeter-5.6.3/bin/result/resp</stringProp>
<boolProp name="FileSaver.errorsonly">false</boolProp>
<boolProp name="FileSaver.successonly">false</boolProp>
<boolProp name="FileSaver.skipsuffix">false</boolProp>
<boolProp name="FileSaver.skipautonumber">false</boolProp>
</ResultSaver>
<hashTree/>
</hashTree>
</hashTree>
</hashTree>
</hashTree>
</jmeterTestPlan>
絵的にはこんな感じです。
DBとWebLogic(Managed Server)が既に起動している状態であれば画面上部の緑ボタン(実行ボタン)押下でテスト・プランの動作確認が可能です。ただしこのままだと緑ボタンを押してもボタンの色が変わるだけで画面に変化がなく、ちゃんと動いているかどうかがわかりません。
スレッドによるHTTPリクエスト(DBインスタンス名取得サーブレットのコール)が正常に行われていることを確認するにはスレッド・グループにView Result Treeを追加します。テスト・プランを実行してからView Result Treeをクリックするとスレッドの実行結果が表示されます。
なお、View Result Treeをつけてテスト・プランを長時間実行するとリクエストの実行情報がガンガン書き込まれてログが肥大化してします。なので動作確認が終わったらView Result Treeは削除しておきます。
SQLリクエスト振り分け集計シェル/集計停止シェル作成
SQLリクエスト振り分け確認用テスト・プランはスレッドがコールしたDBインスタンス名取得サーブレットの応答を結果ファイルとしてresultディレクトリに出力します。
JMeter(テスト・プラン)の起動と結果ファイルの集計をワンセットで実行するSQLリクエスト振り分け集計シェルをJMeterのbinディレクトリに作成します。
<JMeterインストール・ディレクトリ>/bin/RES_SUMMARY.sh(クリックで表示)
#!/bin/bash
function RES_SUMMARY {
find ${RES_DIR} -mmin +0.05 -type f -name '*.unknown' -exec mv {} ${SUM_DIR}/ \;
COL_TIME="$(date "+%Y/%m/%d %H:%M:%S")"
PRDB1=$(grep prdb1 ${SUM_DIR}/*.unknown 2>/dev/null | wc -l)
PRDB2=$(grep prdb2 ${SUM_DIR}/*.unknown 2>/dev/null | wc -l)
echo "${COL_TIME} prsdb01:${PRDB1} prsdb02:${PRDB2}" | tee -a ${SUM_LOG}
rm ${SUM_DIR}/*.unknown 1>>/dev/null 2>&1
}
BIN_DIR=/home/oracle/jmeter/apache-jmeter-5.6.3/bin
EXE_CMD=${BIN_DIR}/jmeter.sh
SCN_FIL=${BIN_DIR}/RCLB_TEST.jmx
SCN_LOG=${BIN_DIR}/STD_HTTP_Request.log
RES_DIR=${BIN_DIR}/result
SUM_DIR=${BIN_DIR}/result_sum
RUN_FLG=${BIN_DIR}/FLG_RUN_RES_SUMMARY
SUM_LOG=${BIN_DIR}/SUM_RESULT.log
CHK_SEC=60
if [ ! -x "${EXE_CMD}" ];then
echo "jmeter.sh does not exist."
exit 1
elif [ ! -f "${SCN_FIL}" ];then
echo "scenario file does not exist."
exit 1
fi
if [ ! -d "${RES_DIR}" ];then
mkdir ${RES_DIR}
fi
if [ ! -d "${SUM_DIR}" ];then
mkdir ${SUM_DIR}
fi
if [ ! -f "${RUN_FLG}" ] ; then
touch ${RUN_FLG}
fi
if [ -f "${SUM_LOG}" ] ; then
mv ${SUM_LOG} ${SUM_LOG}.$(date +"%Y%m%d%H%M%S")
fi
rm -f ${RES_DIR}/*.unknown 1>>/dev/null 2>&1
rm -f ${SUM_DIR}/*.unknown 1>>/dev/null 2>&1
echo "----------------------------------------------------------------" | tee -a ${SUM_LOG}
echo "JMeter HTTP Request scenario execution start --"`date "+%Y/%m/%d %H:%M:%S"` | tee -a ${SUM_LOG}
nohup ${EXE_CMD} -n -t ${SCN_FIL} > ${SCN_LOG} 2>&1 &
sleep 10
echo "---------------------------------------" | tee -a ${SUM_LOG}
echo " Start Aggregating results --"`date "+%Y/%m/%d %H:%M:%S"` | tee -a ${SUM_LOG}
echo "----------------------" | tee -a ${SUM_LOG}
while [ -f "${RUN_FLG}" ] ; do
if [ ! -n "$(ls -A ${RES_DIR}/*.unknown 2>/dev/null)" ];then
continue
fi
NEXT_EXEC=$(date -d "${CHK_SEC} second" +%Y%m%d%H%M%S)
RES_SUMMARY
while [ $(date "+%Y%m%d%H%M%S") -lt ${NEXT_EXEC} ] ;do
if [ ! -f "${RUN_FLG}" ];then
RES_SUMMARY
break
else
sleep 1
fi
done
done
echo "----------------------------------------------------------------" | tee -a ${SUM_LOG}
echo "JMeter HTTP Request scenario execution completed --"`date "+%Y/%m/%d %H:%M:%S"` | tee -a ${SUM_LOG}
exit
SQL振り分け集計シェルはバックグラウンドでJMeterを起動するのでCTL+Cでシェルの実行を強制終了してもJMeterは止まりません。そこでJMeterと振り分け集計の両方を停止するシェルも作成しておきます。
<JMeterインストール・ディレクトリ>/bin/STOP_RES_SUMMARY.sh(クリックで表示)
#!/bin/bash
BIN_DIR=/home/oracle/jmeter/apache-jmeter-5.6.3/bin
EXE_CMD=${BIN_DIR}/shutdown.sh
RES_DIR=${BIN_DIR}/result
SCN_FIL=RCLB_TEST.jmx
SUM_DIR=${BIN_DIR}/result_sum
RUN_FLG=${BIN_DIR}/FLG_RUN_RES_SUMMARY
CHK_SEC=120
if [ ! -x "${EXE_CMD}" ];then
echo "shutdown.sh does not exist."
exit 1
fi
if [ ! -f "${RUN_FLG}" ];then
echo "${RUN_FLG} does not exist."
exit 1
fi
if [ ! -d "${RES_DIR}" ];then
echo "${RES_DIR} does not exist."
exit 1
fi
${EXE_CMD}
for ((i=0;i<${CHK_SEC};i++));do
if [ $(ps -ef | grep jmeter | grep -c ${SCN_FIL}) -eq 0 ];then
rm ${RUN_FLG}
break
else
sleep 1
fi
done
exit
DBサーバの準備
負荷掛け用テーブル
DBインスタンスへの負荷掛けはSQLで実行します。現在PDBにはユーザ・テーブルが何もないのでまずは適当なデータが入ったテーブルをPDBUSERのスキーマに作成します。
DB負荷生成用テーブルおよびデータ作成(クリックで表示)
【prsdb01 / oracleユーザで実行】
---------- -------------------------------------------------------------------
# SQL*Plus起動、PDBUSERでPDBにログイン
sqlplus pdbuser/pdbuser@prpdb
------------------ここからSQL*Plus------------------
-- 負荷掛け用テーブル①作成
create table TEST_TBL1 (
NO number,
CLSS varchar2(8),
NAME varchar2(16),
ADDR varchar2(20),
MEMO varchar2(1000))
tablespace USERTBL01;
-- 負荷掛け用テーブル①にデータ格納
DECLARE
-- 挿入するレコード数
V_COUNT int := 10000;
RND_STR varchar2(1044);
BEGIN
FOR i IN 1..V_COUNT LOOP
RND_STR := DBMS_RANDOM.STRING('X', 1044);
insert into TEST_TBL1 values
(
i, --NO
substr(RND_STR,1,8), -- CLSS
substr(RND_STR,9,16), -- NAME
substr(RND_STR,25,20), -- ADDR
substr(RND_STR,45,1000) -- MEMO
);
END LOOP;
-- トランザクションをコミット
commit;
END;
/
-- 負荷掛け用テーブル①に10000件のレコードが作成されたことを確認
select count(*) from TEST_TBL1;
-- 負荷掛け用テーブル①に主キー・インデックス作成
alter table TEST_TBL1 add constraint IDX_TEST_TBL1 primary key
(NO,CLSS,NAME,ADDR)
using index tablespace USERIDX01;
-- 負荷掛け用テーブル②を作成
create table TEST_TBL2 tablespace USERTBL01 as select * from TEST_TBL1;
alter table TEST_TBL2 add constraint IDX_TEST_TBL2 primary key
(NO,CLSS,NAME,ADDR)
using index tablespace USERIDX01;
-- 負荷掛け用テーブル③を作成
create table TEST_TBL3 tablespace USERTBL01 as select * from TEST_TBL1;
alter table TEST_TBL3 add constraint IDX_TEST_TBL3 primary key
(NO,CLSS,NAME,ADDR)
using index tablespace USERIDX01;
-- ログアウト
exit
負荷生成シェル&DBセッション数集計シェル
DBサーバ#1でDBへの負荷掛けを行うシェル(親シェル・子シェル)とDBセッション数集計シェル、SQLスクリプトを作成して各ノードに配布します。
【prsdb01 / oracleユーザで実行】
-----------------------------------------------------------------------------
# oracleユーザのホーム・ディレクトリに移動(カレント・ディレクトリががホーム・ディレクトリ以外の場合)
cd
# AGL(RCLB)テスト用のディレクトリを作成
mkdir -p RCLB_TEST
# AGL(RCLB)テスト用のディレクトリに移動
cd RCLB_TEST
# 負荷生成シェル(親シェル)を作成
vi RCLB_TEST.sh
# 負荷生成シェル(子シェル)を作成
vi RCLB_TEST_SUB.sh
# DBセッション数集計シェル作成
vi RCLB_SESS.sh
# DBセッション数集計用SQLスクリプトを作成
vi RCLB_SESS.sql
# 作成したシェルに実行権限付与
chmod u+x RCLB_*.sh
# RCLB_TESTディレクトリを各ノードに配布
scp -r /home/oracle/RCLB_TEST prsdb02:~/
scp -r /home/oracle/RCLB_TEST prsdb03:~/
【負荷生成シェル(親シェル)】
/home/oracle/RCLB_TEST/RCLB_TEST.sh(クリックで表示)
#!/bin/bash
# BASE DIRECTORY
BASE_DIR=/home/oracle/RCLB_TEST
# Number of concurrent child shell script executions
SESS_CNT=50
# Child shell script submission delay time
DELAY_SEC=0.25
# Declaration of an array for storing the child shell process ID
declare -a ARRAY_PID=()
# Maximum execution time(default)
MAX_EXE_TIME=600
# End confirmation interval
CHK_SEC=5
# Sub Shell Script
SUB_SHELL=${BASE_DIR}/RCLB_TEST_SUB.sh
# Execution flag
EXE_FLG=${BASE_DIR}/FLG_EXE_RCLB_TEST
# Load log file
LOG_FILE=${BASE_DIR}/RCLB_TEST.log
# SQL spool file
SPOOL=${BASE_DIR}/RCLB_TEST_RESULT.log
#PID list
PID_LIST=${BASE_DIR}/RCLB_TEST.pid
# Elapsed time
ELPS=0
# argument Checking
if [ $# -ne 0 ] ;then
expr $1 + 1 > /dev/null 2>&1
if [ $? -eq 0 ];then
if [ $1 -ge 1 ];then
MAX_EXE_TIME=$1
fi
fi
fi
# user check
if [ "$(whoami)" != "oracle" ]; then
echo "This shell must be run by the oracle user."
exit 1
fi
# directory and file check
if [ -z "${BASE_DIR}" ]; then
echo "Base directory not set."
exit 1
elif [ ! -d "${BASE_DIR}" ]; then
echo "Base directory does not exist."
exit 1
fi
if [ ! -x "${SUB_SHELL}" ]; then
echo "Child shell does not exist."
exit 1
fi
# old logfile archive or clear
if [ -f "${LOG_FILE}" ] ; then
mv ${LOG_FILE} ${LOG_FILE}.$(date +"%Y%m%d%H%M")
fi
if [ -f "${SPOOL}" ] ; then
rm -f ${SPOOL}
fi
if [ -f "${PID_LIST}" ]; then
rm -f ${PID_LIST}
fi
echo "----------------------------------------------------------------------" | tee -a ${LOG_FILE}
echo "DB instance load generation begins. -- "$(date "+%Y/%m/%d %H:%M:%S") | tee -a ${LOG_FILE}
echo "Target load generation time:${MAX_EXE_TIME} sec." | tee -a ${LOG_FILE}
# child shell script execution continuation flag generation
# (Remove this flag if you want to stop the shell.)
if [ ! -f "${EXE_FLG}" ];then
touch ${EXE_FLG}
fi
# Run a child shell script in the background
for ((i=0;i<${SESS_CNT};i++));do
${SUB_SHELL} ${EXE_FLG} > /dev/null 2>&1 &
ARRAY_PID+=($!)
# Recording child shell pid launches
echo "${ARRAY_PID[$i]}-running" >> ${PID_LIST}
done
echo "Load startup complete. " | tee -a ${LOG_FILE}
echo "Start waiting for completion." | tee -a ${LOG_FILE}
echo "-----------------------------" | tee -a ${LOG_FILE}
# Check elapsed time
for ((i=0;i<${MAX_EXE_TIME};i+=${CHK_SEC}));do
if [ ! -f "${EXE_FLG}" ] ; then
echo "Execution flag removed..." | tee -a ${LOG_FILE}
echo "Interrupts the execution of the load-generating shell." | tee -a ${LOG_FILE}
break
else
sleep ${CHK_SEC}
ELPS=$((${i} + ${CHK_SEC}))
if [ $((${ELPS} % 60)) -eq 0 ];then
echo "--- Elapsed Time:$((${ELPS} / 60)) min.---" | tee -a ${LOG_FILE}
else
echo -en "Elapsed Time:${ELPS} sec.\\r"
fi
fi
done
if [ -f "${EXE_FLG}" ];then
rm -f "${EXE_FLG}"
fi
# Wait for child shell to finish
for ((i=0;i<${SESS_CNT};i++));do
sed -i "s/${ARRAY_PID[$i]}-running/${ARRAY_PID[$i]}-stop waiting/g" ${PID_LIST}
wait ${ARRAY_PID[$i]}
sed -i "/${ARRAY_PID[$i]}-stop waiting/d" ${PID_LIST}
done
echo "DB instance load generation completed.-- "$(date "+%Y/%m/%d %H:%M:%S") | tee -a ${LOG_FILE}
echo "----------------------------------------------------------------------" | tee -a ${LOG_FILE}
exit
【負荷生成シェル(子シェル)】
/home/oracle/RCLB_TEST/RCLB_TEST_SUB.sh(クリックで表示)
#!/bin/bash
# oracle user account for executing load-generating SQL
ORA_USR=system
ORA_PWD=oracle
# Load generation SQL execution interval
INTVL=1.5
# Base directory and End flag
EXE_FLG=$1
if [ -z "${EXE_FLG}" ]; then
echo "No exit flag specified"
exit 1
elif [ ! -d "$(dirname ${EXE_FLG})" ]; then
echo "The directory specified in the exit flag is incorrect."
exit 1
elif [ ! -f "${EXE_FLG}" ]; then
echo "The end flag is missing."
exit 1
else
BASE_DIR="$(dirname ${EXE_FLG})"
fi
# SQL spool file
SPOOL=${BASE_DIR}/RCLB_TEST_RESULT.log
(
echo "whenever sqlerror exit 1"
echo "whenever oserror exit 9"
echo "set echo off trimspool on termout off heading off feedback off"
# Remove the "#" from next line when debugging
#echo "spool ${SPOOL} APPEND"
echo "alter session set container = prpdb;"
echo "select count(*) from ("
echo "select /*+ FULL(c) FULL(b) FULL(a) LEADING(a b c) USE_HASH(b c) */ a.NO from"
echo "PDBUSER.TEST_TBL1 a,PDBUSER.TEST_TBL2 b,PDBUSER.TEST_TBL3 c"
echo "where a.NO = b.NO and a.NO = c.NO"
echo "and a.CLSS = b.CLSS and a.CLSS = c.CLSS"
echo "and a.NAME = b.NAME and a.NAME = c.NAME"
echo "and a.ADDR = b.ADDR and a.ADDR = c.ADDR"
echo "order by NO desc);"
while [ -f "${EXE_FLG}" ]; do
sleep ${INTVL}
echo "r"
done)|sqlplus -s ${ORA_USR}/${ORA_PWD}
if [ $? -ne 0 ];then
rm -f "${EXE_FLG}"
fi
exit
【DBセッション数集計シェル】
/home/oracle/RCLB_TEST/RCLB_SESS.sh(クリックで表示)
#!/bin/bash
# BASE DIRECTORY
BASE_DIR=/home/oracle/RCLB_TEST
# Execution flag
EXE_FLG=${BASE_DIR}/FLG_EXE_RCLB_SESS_COUNT
# SQL Script
SQL_FILE=${BASE_DIR}/RCLB_SESS.sql
# SQLPLus spool file
SPOOL=${BASE_DIR}/RCLB_SESS.log
# Session information collection interval(default)
INTVL=60
# Elapsed time
ELPS=0
if [ "$(whoami)" != "oracle" ]; then
echo "This shell must be run by the oracle user."
exit 1
fi
# Argument Checking
if [ $# -ne 0 ] ;then
expr $1 + 1 > /dev/null 2>&1
if [ $? -eq 0 ];then
if [ $1 -ge 1 ];then
INTVL=$1
fi
fi
fi
# Remove this flag if you want to stop the shell.
if [ ! -f "${EXE_FLG}" ];then
touch ${EXE_FLG}
fi
if [ -f "${SPOOL}" ] ; then
mv ${SPOOL} ${SPOOL}.$(date +"%Y%m%d%H%S")
fi
echo "DB session count begins. -- "$(date "+%Y/%m/%d %H:%M:%S")
echo "------------------------"
echo " (Session information collection interval:${INTVL})"
# Run a child shell script in the background
while [ -f "${EXE_FLG}" ]; do
sqlplus -S / as sysdba @${SQL_FILE} ${SPOOL}
for ((i=0;i<${INTVL};i++));do
if [ ! -f "${EXE_FLG}" ];then
break
else
sleep 1
fi
done
ELPS=$((${ELPS} + ${INTVL}))
echo "--- Elapse Time:${ELPS} ---"
done
echo "DB session count completed.-- "$(date "+%Y/%m/%d %H:%M:%S")
exit
【DBセッション数集計用SQLスクリプト】
/home/oracle/RCLB_TEST/RCLB_SESS.sql(クリックで表示)
whenever sqlerror exit 1
whenever oserror exit 9
set trimspool on termout on head off feedback off verify off echo off
set lines 1000 pages 0
col INST_ID format 99
col TM_STMP format a20
col MACHINE format a7 trunc
col MODULE format a10 trunc
col USERNAME format a8 trunc
spool &1 APPEND
select to_char(sysdate,'YYYY/MM/DD HH24:MI:SS') TM_STMP,
INST_ID,MACHINE,MODULE,USERNAME,count(*)
from GV$SESSION
where
USERNAME in ('PDBUSER','SYSTEM')
group by INST_ID,MACHINE,MODULE,USERNAME
order by INST_ID;
spool off;
exit
負荷生成シェルの稼働時間はデフォルトで10分間、引数に秒数を指定して変更することが可能です。シェルの実行を途中で停止する場合はフラグファイル(FLG_EXE_RCLB_TEST)を削除します。
このシェルで実行する子シェルの実行並列度は50、子シェルのリクエスト投入間隔は1.5秒に設定しています。子シェルで実行しているSQLの内容もそうですが実行並列度、リクエスト投入間隔は私の環境(仮想マシンvCPU:4個、ホストCPU:Xeon(R) CPU E5-2690 0 @ 2.90GHz×16 core)でDBサーバのCPU使用率が+15%~20%となるように適当に調整したらこうなった、というだけで他に根拠はありません。
DBセッション数集計シェルには実行時間の設定がなく、CTL+Cで強制終了するかフラグファイル(FLG_EXE_RCLB_SESS_COUNT)を削除するまで実行を継続します。
このシェルのセッション数集計間隔はデフォルトを60秒に設定しています。引数に秒数を指定して変更することが可能です。
DB及びPDBの再起動
シェルを作成して動作確認をざっと済ませたら一旦DBを再起動します。
【prsdb01 / oracleユーザで実行】
-----------------------------------------------------------------------------
# すべてのDBインスタンスを停止
srvctl stop database -db prdb
# すべてのDBインスタンスを起動
srvctl start database -db prdb
# PDBの状態を確認
srvctl status pdb -db prdb -pdb prpdb
→ prsdb01,prsdb02でPDBが起動していることを確認
# 起動していないPDBがあればPDBを起動
srvctl start pdb -db prdb -pdb prpdb
Teraterm画面追加立ち上げ
検証では負荷を掛けたりCPUをモニタリングしたりと各サーバで複数の作業を平行するのであらかじめ各サーバに対して追加のTeraterm画面を起動しておきます。なお、最初に立ち上げた(元々起動していた)Teraterm画面を画面1、追加で立ち上げたTeraterm画面を画面2とします。
AGL(RCLB)動作検証
検証1.セッションの動的分散(初期セッション)
検証内容
AGLの接続プール容量(初期、最小、最大共通)は200なのでAPサーバ#2でManaged Serverを起動すると各ノードに対して合計200本のDBセッションが生成されます。
この200本のセッションは2台のノードに対して各100本が毎回均等に分散されるわけではなく大抵は90:110だとか103:97といった具合に微妙にばらけますが、暫く時間を置くといつの間にか各ノード 100本に均衡化しています。
今までは「あ、なんかAGLが自動調整してるっぽい」ぐらいの認識でこうしたセッションの状態変化をスルーしていましたが今回はAGLの検証ということで初期セッションがノード間で均衡化するまでの挙動を真面目に確認したいと思います。
【検証手順】
| No. | 対象サーバ | 画面 | 実行手順 | 説明 |
| 1 | DBサーバ#3 | 1 | /home/oracle/RCLB_TEST/RCLB_SESS.sh | DBセッション数集計開始 |
| 2 | APサーバ#2 | 1 | /opt/app/oracle/bin/startWebLogic_prs.sh /opt/app/oracle/bin/startManagedWebLogic_prs.sh | WebLogic起動 |
| 3 | DBサーバ#3 | 1 | RCLB_SESS.shの標準出力を監視 | ノード間セッション数均衡化確認 |
| 4 | DBサーバ#3 | 2 | rm /home/oracle/RCLB_TEST/FLG_EXE_RCLB_SESS_COUNT | DBセッション数集計停止 |
| 5 | APサーバ#2 | 1 | /opt/app/oracle/bin/stopWebLogic_prs.sh /opt/app/oracle/bin/stopManagedWebLogic_prs.sh | WebLogic停止 |
検証結果
以下、DBサーバ#3で実行したDBセッション数集計シェルの出力結果(標準出力)です。
[root@prsdb03 ~]# su - oracle
[oracle@prsdb03 ~]$ cd RCLB_TEST/
[oracle@prsdb03 RCLB_TEST]$ ./RCLB_SESS.sh
DB session count begins. -- 2025/12/20 19:16:21
------------------------
(Session information collection interval:60)
--- Elapse Time:60 ---
2025/12/20 19:17:21 1 prsap02 Server PDBUSER 97
2025/12/20 19:17:21 2 prsap02 Server PDBUSER 103
--- Elapse Time:120 ---
2025/12/20 19:18:22 1 prsap02 Server PDBUSER 99
2025/12/20 19:18:22 2 prsap02 Server PDBUSER 101
--- Elapse Time:180 ---
2025/12/20 19:19:22 1 prsap02 Server PDBUSER 100
2025/12/20 19:19:22 2 prsap02 Server PDBUSER 100
--- Elapse Time:240 ---
2025/12/20 19:20:22 1 prsap02 Server PDBUSER 100
2025/12/20 19:20:22 2 prsap02 Server PDBUSER 100
--- Elapse Time:300 ---
DB session count completed.-- 2025/12/20 19:20:29
[oracle@prsdb03 RCLB_TEST]$
※出力結果は右からサンプリング日時、インスタンス番号、、クライアントのホスト名、プログラム、ユーザー、セッション数
Managed Server起動直後の初期セッション数はDBサーバ#1が97本、DBサーバ#2が103本でそれから2分後には各ノード100本と均衡しています。
この結果(標準出力)はDBセッション数集計シェルのサンプリング間隔をデフォルトの1分間で取得しているので毎分1、2本のペースでただゆっくり移動しているようにしか見えませんがDBセッション数集計シェルの集計間隔を10秒に設定して確認すると実際には30秒間隔で切断と接続を繰り返していることがわかります。
DBセッション数集計シェル出力結果(集計間隔 10秒・クリックで表示)
[root@prsdb03 ~]# su - oracle
[oracle@prsdb03 ~]$ cd RCLB_TEST/
[oracle@prsdb03 RCLB_TEST]$ ./RCLB_SESS.sh 10
DB session count begins. -- 2026/01/22 22:15:50
------------------------
(Session information collection interval:10)
--- Elapse Time:10 ---
--- Elapse Time:20 ---
--- Elapse Time:30 ---
--- Elapse Time:40 ---
--- Elapse Time:50 ---
2026/01/22 22:16:40 1 prsap02 Server PDBUSER 11
2026/01/22 22:16:40 2 prsap02 Server PDBUSER 7
--- Elapse Time:60 ---
2026/01/22 22:16:50 1 prsap02 Server PDBUSER 103
2026/01/22 22:16:50 2 prsap02 Server PDBUSER 97
--- Elapse Time:70 ---
2026/01/22 22:17:00 1 prsap02 Server PDBUSER 103
2026/01/22 22:17:00 2 prsap02 Server PDBUSER 97
--- Elapse Time:80 ---
2026/01/22 22:17:10 1 prsap02 Server PDBUSER 103
2026/01/22 22:17:10 2 prsap02 Server PDBUSER 97
--- Elapse Time:90 ---
2026/01/22 22:17:20 1 prsap02 Server PDBUSER 103
2026/01/22 22:17:20 2 prsap02 Server PDBUSER 96
--- Elapse Time:100 ---
2026/01/22 22:17:30 1 prsap02 Server PDBUSER 104
2026/01/22 22:17:30 2 prsap02 Server PDBUSER 96
--- Elapse Time:110 ---
2026/01/22 22:17:40 1 prsap02 Server PDBUSER 104
2026/01/22 22:17:40 2 prsap02 Server PDBUSER 96
--- Elapse Time:120 ---
2026/01/22 22:17:51 1 prsap02 Server PDBUSER 103
2026/01/22 22:17:51 2 prsap02 Server PDBUSER 96
--- Elapse Time:130 ---
2026/01/22 22:18:01 1 prsap02 Server PDBUSER 104
2026/01/22 22:18:01 2 prsap02 Server PDBUSER 96
--- Elapse Time:140 ---
2026/01/22 22:18:11 1 prsap02 Server PDBUSER 104
2026/01/22 22:18:11 2 prsap02 Server PDBUSER 96
--- Elapse Time:150 ---
2026/01/22 22:18:21 1 prsap02 Server PDBUSER 103
2026/01/22 22:18:21 2 prsap02 Server PDBUSER 96
--- Elapse Time:160 ---
2026/01/22 22:18:31 1 prsap02 Server PDBUSER 104
2026/01/22 22:18:31 2 prsap02 Server PDBUSER 96
--- Elapse Time:170 ---
2026/01/22 22:18:41 1 prsap02 Server PDBUSER 104
2026/01/22 22:18:41 2 prsap02 Server PDBUSER 96
--- Elapse Time:180 ---
2026/01/22 22:18:51 1 prsap02 Server PDBUSER 103
2026/01/22 22:18:51 2 prsap02 Server PDBUSER 96
--- Elapse Time:190 ---
2026/01/22 22:19:01 1 prsap02 Server PDBUSER 103
2026/01/22 22:19:01 2 prsap02 Server PDBUSER 97
--- Elapse Time:200 ---
2026/01/22 22:19:11 1 prsap02 Server PDBUSER 103
2026/01/22 22:19:11 2 prsap02 Server PDBUSER 97
--- Elapse Time:210 ---
2026/01/22 22:19:21 1 prsap02 Server PDBUSER 102
2026/01/22 22:19:21 2 prsap02 Server PDBUSER 97
--- Elapse Time:220 ---
2026/01/22 22:19:31 1 prsap02 Server PDBUSER 102
2026/01/22 22:19:31 2 prsap02 Server PDBUSER 98
--- Elapse Time:230 ---
2026/01/22 22:19:41 1 prsap02 Server PDBUSER 102
2026/01/22 22:19:41 2 prsap02 Server PDBUSER 98
--- Elapse Time:240 ---
2026/01/22 22:19:51 1 prsap02 Server PDBUSER 101
2026/01/22 22:19:51 2 prsap02 Server PDBUSER 98
--- Elapse Time:250 ---
2026/01/22 22:20:01 1 prsap02 Server PDBUSER 101
2026/01/22 22:20:01 2 prsap02 Server PDBUSER 99
--- Elapse Time:260 ---
2026/01/22 22:20:11 1 prsap02 Server PDBUSER 101
2026/01/22 22:20:11 2 prsap02 Server PDBUSER 99
--- Elapse Time:270 ---
2026/01/22 22:20:22 1 prsap02 Server PDBUSER 100
2026/01/22 22:20:22 2 prsap02 Server PDBUSER 99
--- Elapse Time:280 ---
2026/01/22 22:20:32 1 prsap02 Server PDBUSER 100
2026/01/22 22:20:32 2 prsap02 Server PDBUSER 100
--- Elapse Time:290 ---
2026/01/22 22:20:42 1 prsap02 Server PDBUSER 100
2026/01/22 22:20:42 2 prsap02 Server PDBUSER 100
--- Elapse Time:300 ---
2026/01/22 22:20:52 1 prsap02 Server PDBUSER 100
2026/01/22 22:20:52 2 prsap02 Server PDBUSER 100
--- Elapse Time:310 ---
DB session count completed.-- 2026/01/22 22:20:54
[oracle@prsdb03 RCLB_TEST]$
「Oracle WebLogic Server JDBCデータ・ソースの管理14c (14.1.2.0.0)」の「実行時ロード・バランシング」のノートに30秒サイクルで接続を見直す記述がありますが実際の動きはだいたいこんな感じなんですね。
実行時ロード・バランシング
ノート
各接続は、AGLデータ・ソースで一定期間ごとにシャットダウンされます。様々なRACインスタンスに割り当てられた接続がFANロード・バランシング・アドバイザのランタイム・ロード・バランシングと一致しない場合は、過重インスタンスへの接続が破棄され、新しい接続が開かれます。このプロセスは、デフォルトでは30秒ごとに発生します。この動作を調整するには、接続のリバランスが行われるまでシステムが待機する時間(秒)を指定するシステム・プロパティweblogic.jdbc.gravitationShrinkFrequencySecondsを使用します。値を0にすると、再バランシング処理が無効になります。
※ちなみにこのノートには「各接続は、AGLデータ・ソースで一定期間ごとにシャットダウンされます。」とあります。接続が勝手に閉じられちゃマズいんじゃないのと思って英語版のマニュアルを確認したらオリジナルのドキュメントは「Connections may be shut down periodically on AGL data sources.」(google翻訳:AGL データ ソースでは接続が定期的にシャットダウンされる場合があります。)となっていました。「シャットダウンされます。」と「シャットダウンされる場合があります。」ではだいぶニュアンスが違いますよねぇ…
検証2.セッションの動的分散(片ノード稼働上昇時)
検証内容
各ノードのセッション数が均衡したところで次の検証です。AGLからSQLリクエストは何も飛ばさない状態、つまりAGLがDBにただセッションを張っただけの状態でDBサーバ#1に10分間負荷を掛けて各ノードのセッションがどうなるかを確認してみたいと思います。
【検証手順】
| No. | 対象サーバ | 画面 | 実行手順 | 説明 |
| 1 | DBサーバ#1 DBサーバ#2 | 2 | sar -u 60 | tee sar_$(hostname -s)_$(date +”%Y%m%d%H%M”.log | CPU使用率取得開始 |
| 2 | DBサーバ#3 | 1 | /home/oracle/RCLB_TEST/RCLB_SESS.sh | DBセッション数集計開始 |
| 3 | APサーバ#2 | 1 | /opt/app/oracle/bin/startWebLogic_prs.sh /opt/app/oracle/bin/startManagedWebLogic_prs.sh → ノード間のセッション数が均衡するまで待機 | WebLogic起動 |
| 4 | DBサーバ#1 | 1 | /home/oracle/RCLB_TEST/RCLB_TEST.sh (負荷生成時間10分) | 片ノード負荷生成開始 |
| 5 | DBサーバ#3 | 1 | RCLB_SESS.shmの標準出力監視(1h) | セッション状態確認 |
| 6 | APサーバ#2 | 1 | /opt/app/oracle/bin/stopWebLogic_prs.sh /opt/app/oracle/bin/stopManagedWebLogic_prs.sh | |
| 7 | DBサーバ#3 | 2 | rm /home/oracle/RCLB_TEST/FLG_EXE_RCLB_SESS_COUNT | DBセッション数集計停止 |
| 8 | DBサーバ#1 DBサーバ#2 | 2 | CTL+C | CPU使用率取得停止 |
検証結果
!?
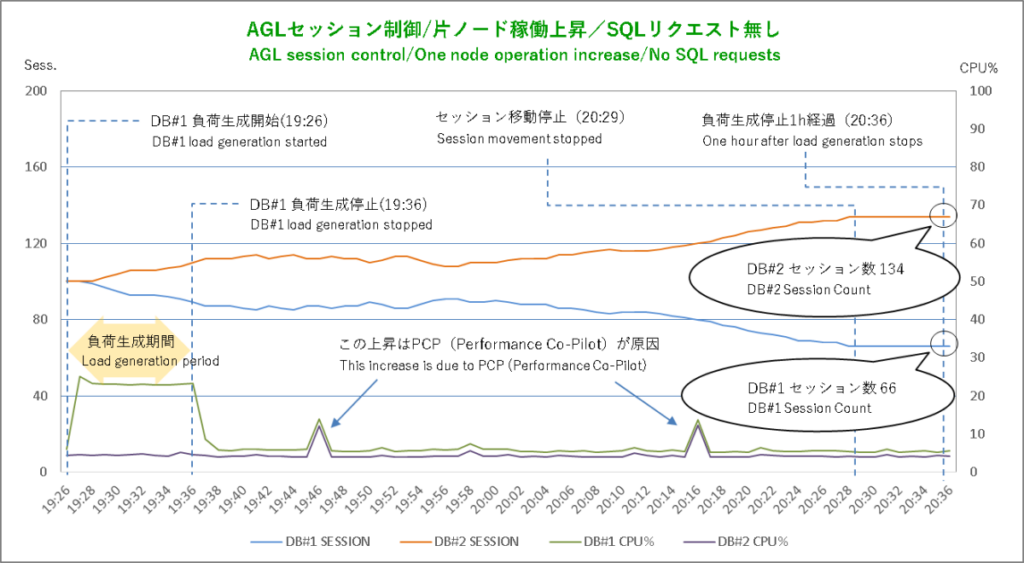
なんかちょっとおかしなことになりました。
「Oracle WebLogic Server JDBCデータ・ソースの管理」には「AGLデータ・ソースは、データベースが発行するOracle FANイベントに基づいて、ランタイム接続ロード・バランシング(RCLB)を使用し、Oracle RACの各インスタンスに接続を分散します。」と書かれています。なので私としてはDBサーバ#1への負荷掛けでそのノードのセッションがDBサーバ#2に移動、負荷掛け終了後にまたDBサーバ#1に復帰という想定でしたが、、、
DBサーバ#1での負荷生成シェル実行によってこのノードのセッションがDBサーバ#2に移動するまではよかったのですが、負荷生成シェルが終了した後もこの移動がなかなか止まりません。最終的にDBサーバ#1が66本、DBサーバ#2が134本となったところでようやく動かなくなりました。
なんで??(もしかしてバ〇?)
設定見直し
サービス設定(DB)
こういうときはちゃっぴいの出番です。で、結論。
負荷掛け終了後も元のノードにセッションが戻ってこない原因はサービスの目標とAGLによるヘルスチェック(DB接続テスト)の組み合わせが悪いんじゃなかろうかというのがちゃっぴいの回答です(つまりバ〇ではなく仕様)。
前に書いた通りAGLが接続する「online_srv」のサービス目標「THROUGHPUT」について、ロード・バランシング・アドバイザ(LBA)の調整基準はサービスレベルでの「作業の処理速度」とドキュメントに記述されています。
この「作業の処理速度」が具体的にどの統計を指しているかまでは書かれていないもののLBAに関連付けられた動的パフォーマンスビューを辿るとおそらく「Calls per second」「DB time per second」「Completed work rate」あたりで、ごく短時間で終わる軽いSQLを一定間隔で定期的に流した場合、こうした統計はDBが無風状態ならノードが変わろうがタイミングが変わろうがサンプリングしたデータにあまり差が出ない。
そしてAGLからSQLリクエストを流していない現状でこのサービスにはヘルスチェックで流れる「ごく短時間で終わる軽いSQL」(select 1 from dual)しか稼働データがありません。
ここから先はややこしい話が長々と続くので非常にざっくりまとめるとLBAはこうしたサービス統計の履歴を各ノードごとに(瞬間的な変動はスルーするよう)指数移動平均的な手法で評価/結果をノード間で比較して作業分散を調整しているのではないかというのがちゃっぴいの推察です。
で、サンプリング統計間で差分がガンガン出まくる状態が継続した場合、つまり負荷掛け中の状況に対してLBAは敏感に反応(作業分散を調整)するけれどもサンプリング統計間で同じような値が延々続く負荷掛け後の無風状態に対しては反応が鈍くなる(サンプリング統計間で差分が出なくて調整が更新されない)んじゃなかろうかと。
LBAの内部仕様は非公開のブラックボックス状態ですからこれが正解かどうかは確かめようがありませんが検証結果がこうなった理由の説明としてはなるほど辻褄が合っているような気はします。
また、サービス目標がSERVICE_TIMEの場合はLBAによる調整の元ネタはおそらく「Average Service Time(平均応答時間)」なのでごく短時間で終わる軽いSQLは処理時間にバラツキが出やすいことからLBAの調整にはこちらの方が適している(サービスの稼働状況に反応しやすい)んじゃないかというアドバイスもくれました。
なるほど、SERVICE_TIMEがオンライン向けというのはそういうことだったのか。ということでサービス目標をTHROUGHPUTからSERVICE_TIMEに変更します。
【prsdb01 / oracleユーザで実行】
-----------------------------------------------------------------------------
# 現在のサービス設定を確認
srvctl config service -db prdb -service online_srv
# ロード・バランシング目標を変更
srvctl modify service -db prdb -service online_srv -rlbgoal SERVICE_TIME
# 設定変更後のサービス設定を確認
srvctl config service -db prdb -service online_srv
Grid Infrastructure(RAC)設定
「検証2」の結果(グラフ)をつらつら眺めていてふと気づいたのですが、負荷生成の有無にかかわらずDBサーバ#1のCPU使用率がDBサーバ#2のCPU使用率よりも常時微妙に高くなっています。
試しにグラフの元ネタからCPU使用率の10分平均を算出してノード間で比較してみるとその差は約1.5%でした。
【DBサーバ 平均CPU使用率%(10分平均)】
| サーバ名 | 19:37-19:46 | 19:47-19:56 | 19:57-20:06 | 20:07-20:16 | 20:17-20:26 | 20:27-20:36 | 1時間平均 |
| (DB#1)prsdb01 | 7.0 | 5.7 | 5.9 | 6.5 | 5.5 | 5.5 | 6.0 |
| (DB#1)prsdb01 | 5.0 | 4.1 | 4.4 | 5.0 | 4.2 | 4.2 | 4.5 |
このCPU使用率の差分がLBAの調整に影響するとは思えませんが、何が原因かは少し気になります。
そこで実機を調べてみたらOracle Database QoS Management(Oracle Database QoS管理)が毎分1~2秒間、約40%程度のCPUスパイクを発生させていることがわかりました。
Oracle Database QoS Managementはポリシー管理型データベースのパフォーマンス管理に関連する機能でRAC構成ノードの一台、現在はDBサーバ#1で動いています。Gridインストール時に勝手に構成された機能ですが、そもそも本番サイトのDBは管理者管理型なんでこんなものはまったく必要ありません。
しかもググったらこの機能はOracle 21cで廃止との情報が……
F.1 Oracle Database Quality of Service (QoS) Management is Deprecated and Desupported in Release 21c
<要点抜粋>
Starting in Oracle Database release 21c, Oracle Database Quality of Service (QoS) Management is deprecated and desupported.
<google翻訳>
Oracle Database release 21c以降、Oracle Database Quality of Service(QoS)管理は非推奨およびサポート終了となりました。
いや、だったらデフォルトで無効化しとけよと、、、
Oracle Database QoS Managementは今回の検証と直接関係ありませんが、この際なので無効化してしまいます。
【prsdb01で実行】
-----------------------------------------------------------------------------
# oracleユーザでは権限不足なのでgridユーザにスイッチ
su - grid
# qosmserverの状態を確認
srvctl status Qo
→ 「QoS管理サーバーは有効になっています。」「QoS管理サーバーは、ノードprsdb01で実行中です。」が返される
# qosmserverを停止
srvctl stop qosmserver
# qosmserverを無効化
srvctl disable qosmserver
→ 全ノードのCRSを再起動してqosmserverが起動していない状態(OFFLINE)であればOK(確認は以下のコマンドでも可)。
<gridホーム>/bin/crsctl status res -t
検証3.セッションの動的分散(片ノード稼働上昇時・再)
検証内容
サービス目標をSERVICE_TIMEに変更して片ノード稼働上昇時のセッション制御(SQLリクエストなし)の再検証といきます。
【検証手順】
| No. | 対象サーバ | 画面 | 実行内容 | コマンド |
| 1 | DBサーバ#1 DBサーバ#2 | 2 | CPU使用率取得開始 | sar -u 60 | tee sar_$(hostname -s)_$(date +"%Y%m%d%H%M".log |
| 2 | DBサーバ#3 | 1 | DBセッション数集計開始 | /home/oracle/RCLB_TEST/RCLB_SESS.sh |
| 3 | DBサーバ#3 | 1 | ノード間セッション数均衡まで待機 | -(セッション集計シェル画面出力監視) |
| 4 | DBサーバ#2 | 2 | 負荷生成開始(負荷生成時間10分) | /home/oracle/RCLB_TEST/RCLB_TEST.sh |
| 5 | DBサーバ#3 | 1 | DBセッション状態監視 | -(セッション集計シェル画面出力監視) |
| 6 | DBサーバ#3 | 2 | DBセッション集計停止 | rm /home/oracle/RCLB_TEST/FLG_EXE_RCLB_SESS_COUNT |
| 7 | DBサーバ#1 DBサーバ#2 | 2 | CPU使用率取得停止 | CTL+C |
検証結果
で、その結果。
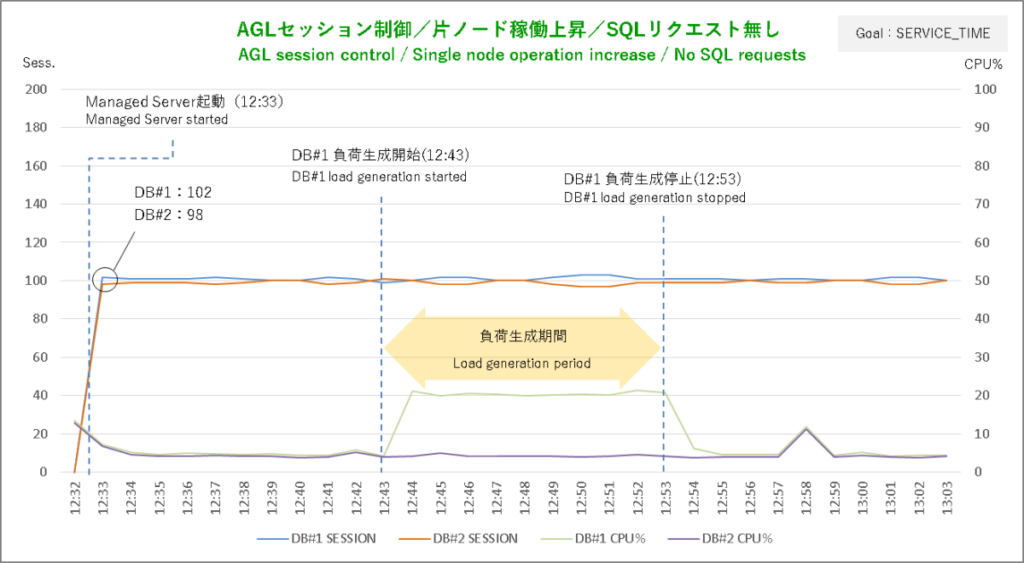
サービス目標を「SERVICE_TIME」に変更したら今度はManaged Server起動直後の初期セッションがノード間で微妙に移動を繰り返して均衡しなくなりました。しかしまあ、どちらかに大きく傾いているわけではないのでとりあえず問題なし。
Managed Server起動後10分待ってもノード間のセッション数が均衡しないのでそこで負荷生成シェル実行です。セッションがややDBサーバ#1に寄り気味だったので負荷掛けの対象ノードもそっちにしました。
これでセッションがどうなったかというとほとんど反応していません。CPU使用率+20%程度の負荷では超軽量SQL(select 1 from dual)の応答時間に全く影響がないんでしょう。
実は私は最初に片ノードへの負荷掛けをやった時にLBAの調整はサービス単位であることをすっかり忘れていました。なのでAGLがDBのサービスにSQLリクエストを飛ばしていない状況で片ノードの稼働が上昇したからといってセッションが移動してしまうこと自体がそもそもダメダメだったわけで、上のグラフにあるような状態が正しい姿です、はい。
AGLによるヘルスチェック(DB接続テスト)の設定
THROUGHPUTとの組み合わせでセッションがおかしな挙動を示す原因となったAGLのDB接続テストですが、実はちゃっぴいからやめてしまえというアドバイスがありました。
ヘルスチェックで使用する超軽量のSQLはLBAの調整を歪めてしまうしそれにAGLはFANイベントによってノード障害を素早く検知・接続切り替えができるのでDB接続テスト(ちゃっぴいの言い方ではヘルスチェック)はいらんでしょ、ということなのですがDB接続テストをやめることによるデメリットを訊ねると「ノード障害発生後、最初に投入したSQLリクエストはエラーとなります。アプリがそれを許容できるシステムならヘルスチェックを止めても問題ありません」とか。いやおまえそれを先に言え
ちゃっぴいはヘルスチェックでまとめてしまっていますが、実際のAGLの設定はアプリに接続を渡す前のテストと未使用の接続を定期的にテストする2パターンに分かれています。LBAの調整を歪めてしまうのは後者だけなのでこれだけ止めてしまうというのはアリかもしれません。
ただしその場合は未使用接続のテストを止めることによる影響、リスクの検討は必要です。また、AGLが接続するサービス「online_srv」はAPサーバ#1のMDSも共用しているのでDB接続テストの設定はそのままとします。
といっても、サービス目標 THROUGHPUTで未使用接続のテストを止める、未使用接続のテスト間隔を長くする(デフォルトの10秒 → 600秒)の2パターンも実際に試してみました。「未使用接続のテストを止める」はそのまんまですが「未使用接続のテスト間隔を長くする」は接続テストによる稼働の上昇を瞬間的な変動としてLBAにスルーさせることが狙いです。
詳細な結果はここに載せませんがそれでどうなったかというと、どちらのパターンでもサービスの外部要因(つまり片ノードでの負荷生成)によるセッションの移動が発生しなくなりました。ヘルスチェック(軽量SQLの定期的な投入)がLBAの調整を歪めてセッションの挙動をおかしくしているんじゃないかというちゃっぴいの推測はあたっていたんですね。
それがわかったところで次の検証、SQLリクエストのバランシングです。
検証4.SQLリクエスト・バランシング
検証内容
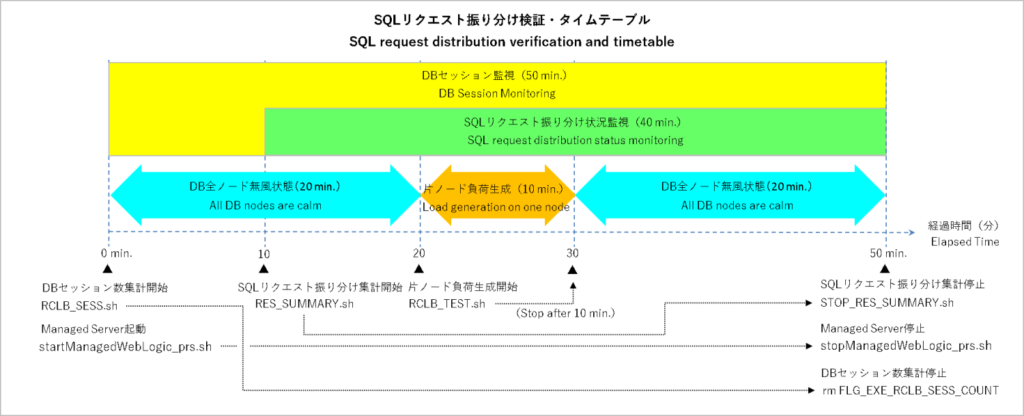
ここからはJMeterのテスト・プラン(SQLリクエスト振り分け確認用テスト・プラン)を使ってAGLからDBにSQLリクエストを飛ばしながらノード間でこれがどう振り分けられるかを検証していきます。
検証手順は片ノード負荷掛けパターンにSQLリクエスト振り分け集計シェル(JMeter起動+振り分け集計)の実行が加わるだけなので細かい話は省略して負荷生成シェルとJMeterテスト・プラン(RCLB_TEST.jmx)の設定だけ載せておきます。
【負荷生成シェル/JMeter設定】
| 設定項目 | 負荷生成シェル | JMeterテスト・プラン |
| 投入SQL | select count() from ( select /+ FULL(c) FULL(b) FULL(a) LEADING(a b c) USE_HASH(b c) */ a.NO from PDBUSER.TEST_TBL1 a,PDBUSER.TEST_TBL2 b,PDBUSER.TEST_TBL3 c where a.NO = b.NO and a.NO = c.NO and a.CLSS = b.CLSS and a.CLSS = c.CLSS and a.NAME = b.NAME and a.NAME = c.NAME and a.ADDR = b.ADDR and a.ADDR = c.ADDR order by NO desc); | select to_char(sysdate,’YYYY/MM/DD HH24:Mi:SS’) || ‘ ‘ || INSTANCE_NAME from V$INSTANCE; |
| 並列度 | 50 | 40 |
| プロセス(スレッド)あたりSQLリクエスト投入間隔 | 1.5s | 2s |
※負荷生成シェルのSQLリクエスト投入間隔は前の応答が戻ってから次のリクエスト投入までの時間(SQLの応答時間+2s=1サイクルの所要時間)ですがJMeterテスト・プランは各スレッドが1分間に30回(1サイクル2s=SQLの応答時間+次のリクエスト投入までの待機時間)です。
どちらのノードに負荷を掛けるかはその時の状況で決めるとして検証のタイム・テーブルはざっとこんな感じです。
検証結果
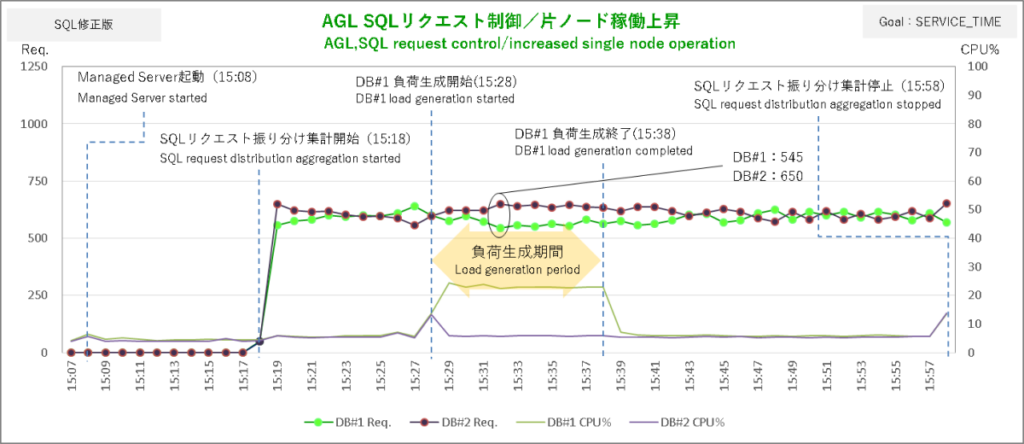
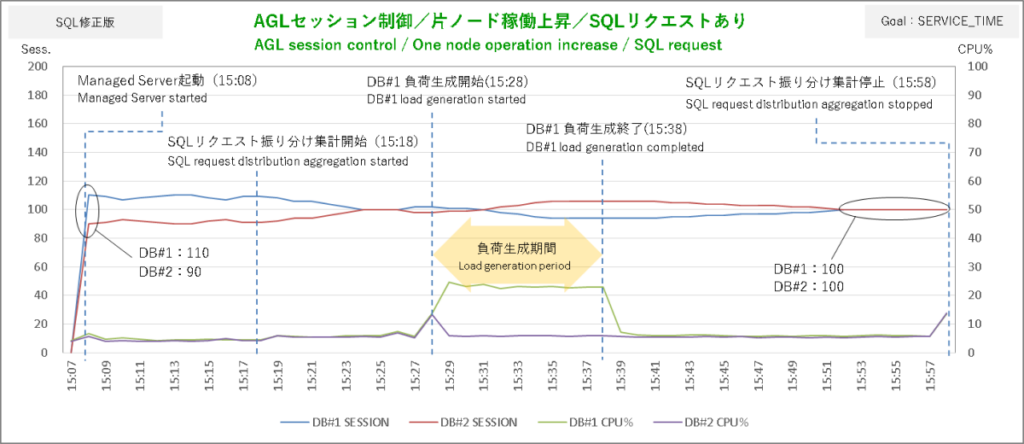
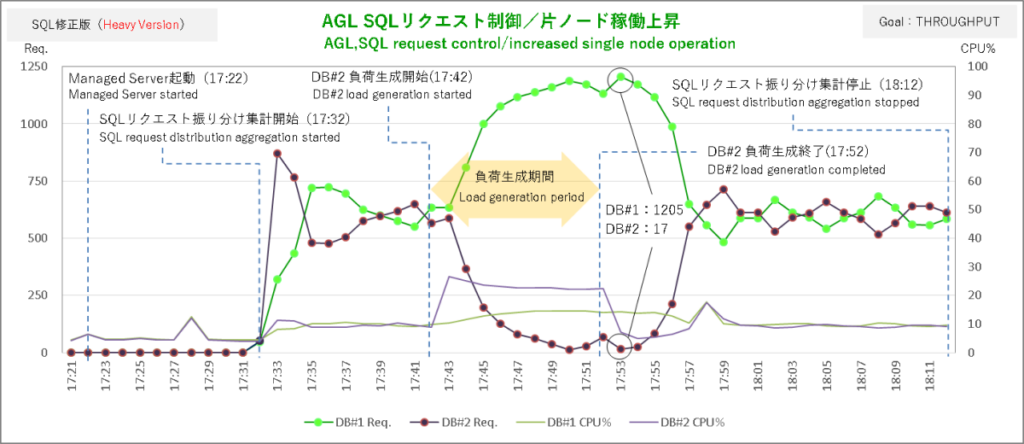
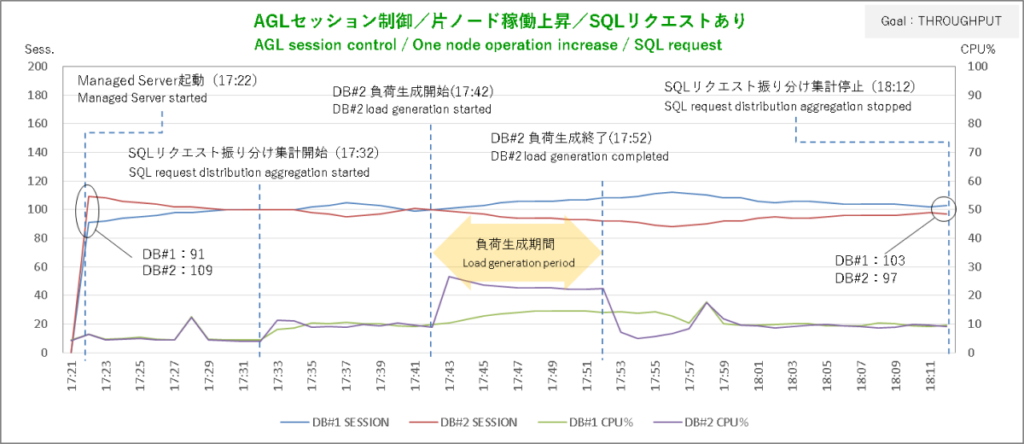
まずはサービス目標 SERVICE_TIMEから。AGLからSQLリクエストを飛ばしてその振り分けがどうなったかというと……、
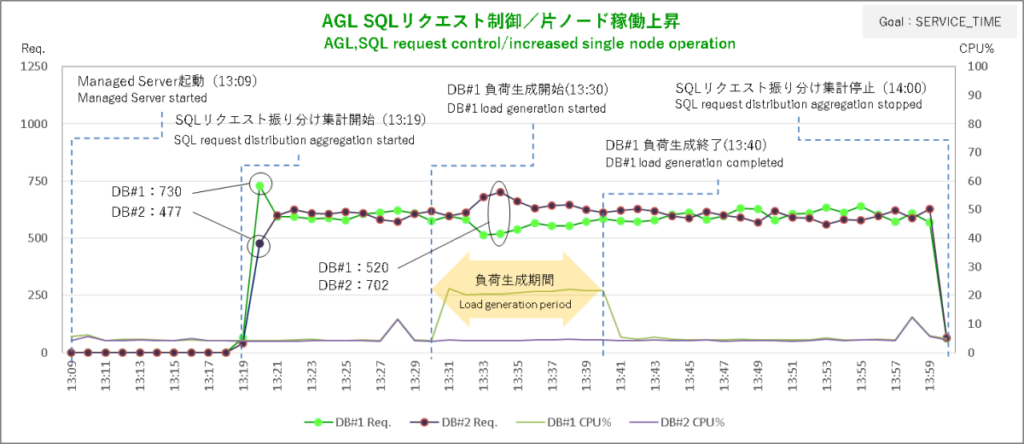
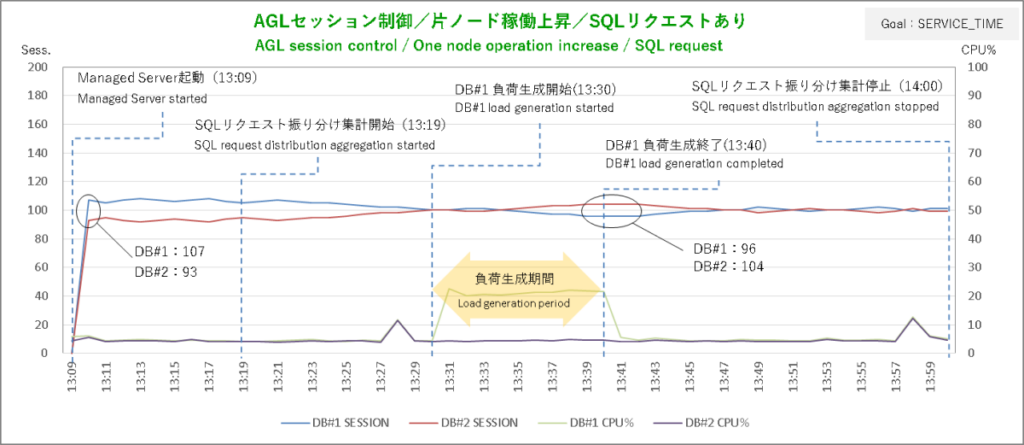
上段のグラフがSQLリクエスト振り分け状況、下段のグラフがセッション状況です。オールイン・ワンにすると見づらくなってしまうので分割しています。
肝心のSQLリクエストの振り分けはなんかそれっぽい結果になりました。
まずSQLリクエストの振り分け集計を開始してからの10分間。初動で発生した大きな偏りを除き各ノードへの振り分け数は概ね均衡しています。
ここでDBサーバ#1で負荷掛けを開始。2分後にSQLリクエストの振り分けはDBサーバ#2に大きく偏り始めて4分後に偏りのピークです。DBサーバ#1とDBサーバ#2で5:7の配分ですから調整量は抑え気味ですね。
まあ、AGLから飛ばしているSQLはライブラリをちょっとつつくレベルの超軽量級ですからCPU使用率+20%程度の負荷がノードにかかったところで実行時間にそれほど影響しないということなんでしょう。
SERVICE_TIMEではDBが無風状態でもバランシングの調整がちょこちょこ入っていて負荷生成終了後に振り分けの偏りがいつ解消したのかはっきりしませんが、セッションのグラフを見ると負荷生成終了2分後あたりで均衡状態に向かい始めているのでおそらくそのあたりじゃないでしょうか。
こうした結果を見ると「ロードバランシング目標 SERVIC_TIMEなら軽量SQLの稼働にも敏感に反応」というちゃっぴいの推測は当たっているようです。
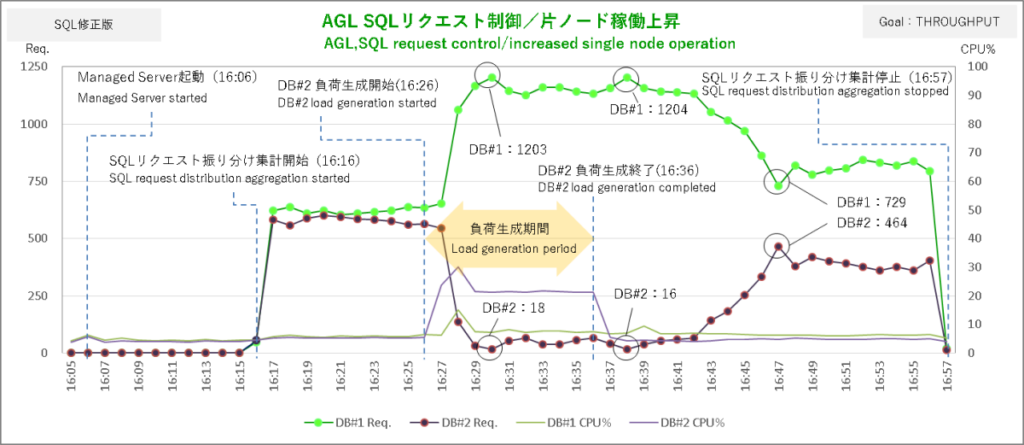
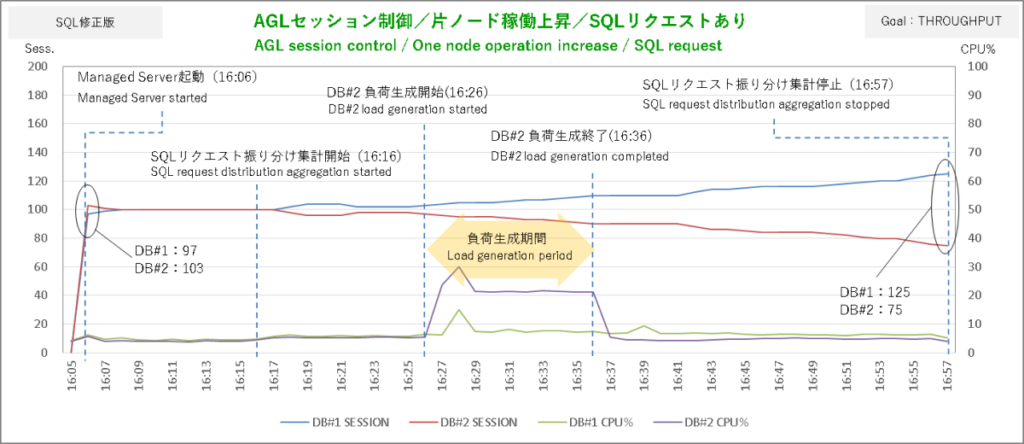
次はサービス目標 THROUGHPUTの結果。今度はDBサーバ#2で負荷を生成しています。
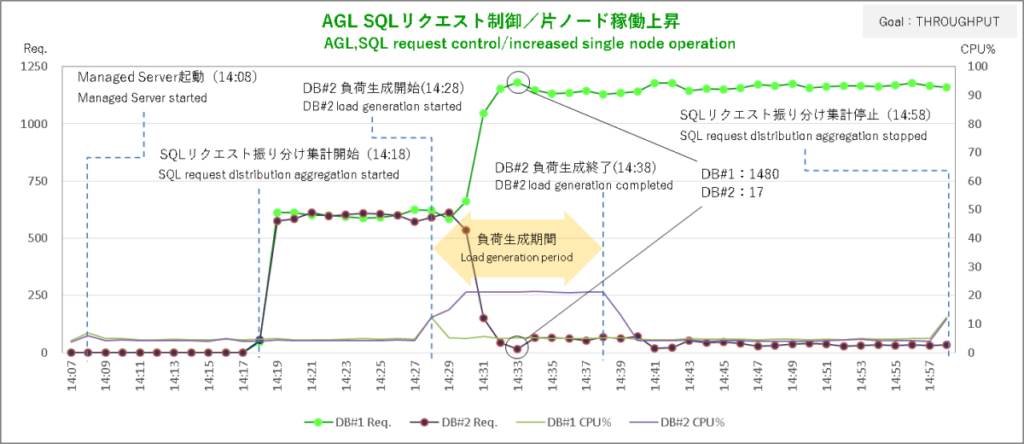
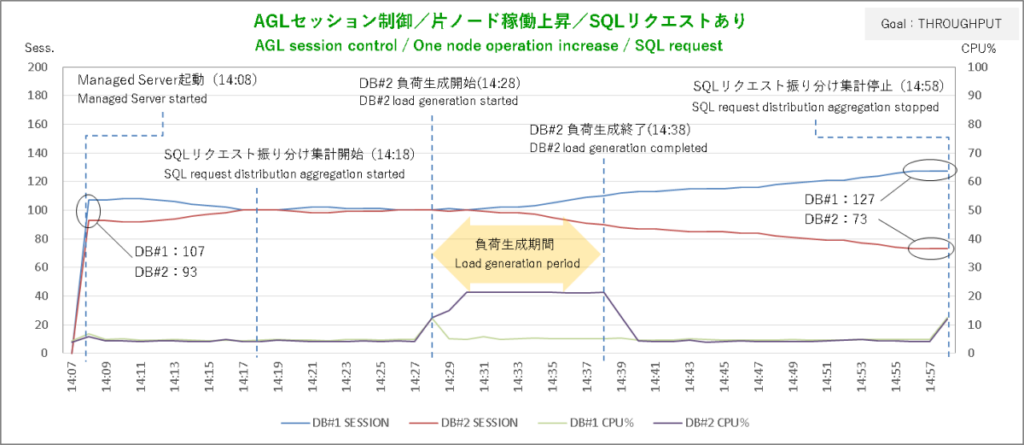
DBサーバ#2での負荷生成開始から2分後にSQLリクエストを思いっきりDBサーバ#1に偏っています。動的分散している感があってここまではなかなか良さげですが負荷生成終了後にその偏りが解消されないのはセッションの移動を確かめたときと同じでまったく使い物になりません。
そのセッションに至ってはバカ一直線にDBサーバ#2 → DBサーバ#1へと移動しまくりです。軽いSQLとTHROUGHPUTの組み合わせはやはりダメなんですかねぇ。
検証5.SQLリクエスト・バランシング(SQL稼働量増加)
検証内容
AGLがDB(RACノード)の稼働状況に応じてSQLリクエストの振り分けを調整していることは確認できましたがリクエスト元であるDBインスタンス名取得サーブレット(InstNameGet)のSQLが軽すぎてSERVICE_TIMEのSQLリクエスト振り分けは控えめだしTHROUGHPUTはダメダメです。
なのでここはSQLの稼働をもうちょっと重くして再検証してみたいと思います。
DBインスタンス名取得サーブレット(InstNameGet)自体はそれなりに使い出があってあまりイジりたくないのでサーブレットが入っているパッケージ(pkgconnchk)に別のサーブレット(InstNameGet2)を追加します。このサーブレットの中身は基本的にInstNameGetと同じでクラス名とSQLテキストの記述箇所だけ変更(応答に使用しないサブクエリを追加)します。
【InstNameGet2 改修箇所】
-----------------------------------------------------------------------------
クラス名:InstNameGet → InstNameGet2
SQLテキスト:
String sql = "select to_char(sysdate,'YYYY/MM/DD HH24:Mi:SS') || ' ' || INSTANCE_NAME from V$INSTANCE";
↓
String sql = "select to_char(sysdate,'YYYY/MM/DD HH24:Mi:SS') || ' ' || vi.INSTANCE_NAME";
sql = sql + " from V$INSTANCE vi, (select count(*) CNT from (";
sql = sql + " select a.NO from PDBUSER.TEST_TBL1 a,PDBUSER.TEST_TBL2 b";
sql = sql + " where a.NO = b.NO and a.CLSS = b.CLSS and a.NAME = b.NAME and a.ADDR = b.ADDR";
sql = sql + " order by NO desc ) ) ptb";
負荷生成シェルのSQLみたく無駄なテーブルの結合でゴリゴリに重くしてしまうとただでさえ薄い検証シチュエーションのリアリティがさらに薄くなってしまうのでなるべくオンラインのSQLチックに索引結合だけにしてみました。
APサーバ#2で改修版アプリのデプロイが終わったらJMeterをGUIで起動します。RCLB_TEST.jmxを開き、HTTPリクエストのパスを以下のように修正・保存で再検証の準備は完了です。
【RCLB_TEST.jmx 改修箇所】 -----------------------------------------------------------------------------Path:/ConnCheck/InstNameGet → /ConnCheck/InstNameGet2
【負荷生成シェル/JMeter設定】
| 設定項目 | 負荷生成シェル | JMeterテスト・プラン |
| 投入SQL | 前回と同じ | </ConnCheck/InstNameGet2> select to_char(sysdate,’YYYY/MM/DD HH24:Mi:SS’) || ‘ ‘ || vi.INSTANCE_NAME from V$INSTANCE vi, (select count(*) CNT from ( select a.NO from PDBUSER.TEST_TBL1 a,PDBUSER.TEST_TBL2 b where a.NO = b.NO and a.CLSS = b.CLSS and a.NAME = b.NAME and a.ADDR = b.ADDR order by NO desc ) ) ptb |
| 並列度 | 50 | 40 |
| プロセス(スレッド)あたりSQLリクエスト投入間隔 | 1.5s | 2s |
検証結果
まずはサービス目標 SERVICE_TIMEの結果。負荷生成シェルはDBサーバ#1で実行しています。
なんだか前回の検証結果(SERVICE_TIMEで実行)よりも負荷掛けによるSQLリクエストの偏りが小さいような……。
負荷生成開始2分後あたりでSQLリクエストの振り分けが対向ノードに向かって一度大きく偏る動きが抑えられてかわりに同じような薄い幅の偏りが長く続いています。アプリのSQLを少し重くしたことで処理時間のバラつきがかえって少なくなったからなんですかね?
お次はサービス目標 THROUGHPUTの結果。負荷生成シェルはDBサーバ#2で実行しています。
こちらは前回の検証結果(THROUGHPUTで実行)と比べてだいぶ差が出ました。
DBサーバ#2での負荷生成終了から2分後(16:36)、DBサーバ#1に大きく偏っていたSQLリクエストが徐々にDBサーバ#2に戻り始めています。しばらくすると急にその勢いが増して各ノード均衡状態に戻るかと思われたのですが、残念ながら16:47にまた反転してDBサーバ#1に偏り始めてしまいました。
しかしこれまでの検証結果と比べれば振り分けの動きは格段に良くなっています。SQLが重くなったことによってAGL(LBA)がDB(ノード)の稼働状況に反応しやすくなったということでしょうか。
なお、グラフの最後(右端)でSQLリクエスト数が両ノードとも0に急減しているのは私があきらめてSQLリクエスト振り分け集計シェルを停止したからです。あとセッションの方はあいかわらずバカ一直線でした。
検証6.SQLリクエスト・バランシング(SQL稼働量さらに増加)
検証内容
OKとはならなかったもののTHROUGHPUTの検証結果がかなりいい線まで行ったのでSQLをもっとバッチ系っぽい感じに重くしてTHROUGHPUTをリトライしたいと思います。
アプリにまた新しいサーブレット(InstNameGet3)を追加してInstNameGet2からコピーしたSQLを編集(副問合せ内を負荷生成シェルのSQLに差し替え)、APサーバ#2のManaged Serverでデプロイします。
【負荷生成シェル/JMeter設定】
| 設定項目 | 負荷生成シェル | JMeterテスト・プラン |
| 投入SQL | 前回と同じ | </ConnCheck/InstNameGet3> select to_char(sysdate,’YYYY/MM/DD HH24:Mi:SS’) || ‘ ‘ || vi.INSTANCE_NAME from V$INSTANCE vi, (select count() CNT from ( select /+ FULL(c) FULL(b) FULL(a) LEADING(a b c) USE_HASH(b c) */ a.NO from PDBUSER.TEST_TBL1 a,PDBUSER.TEST_TBL2 b,PDBUSER.TEST_TBL3 c where a.NO = b.NO and a.NO = c.NO and a.CLSS = b.CLSS and a.CLSS = c.CLSS and a.NAME = b.NAME and a.NAME = c.NAME and a.ADDR = b.ADDR and a.ADDR = c.ADDR order by NO desc ) ) ptb |
| 並列度 | 50 | 40 |
| プロセス(スレッド)あたりSQLリクエスト投入間隔 | 1.5s | 2s |
検証結果
で、その結果。
ようやくまともに動いた・・・・・・
負荷生成シェル終了後、SQLリクエストの偏りが解消されてグラフは見事な山手線。偏り解消後は勢いがつきすぎて酔っ払い運転のおっさんがカウンター当てまくっているような感じになっていますがどちらか一方向に行ったきりではないのでまあ無問題。
セッションの方も2ノード103:97の配分なのでまずまずです。SQLの稼働が重ければTHROUGHPUTでも作業分散の調整がうまく機能することが確認できました。
検証6.SQLリクエスト・バランシング(SQL投入量増加)
検証内容
サービス目標 SERVICE_TIME、THROUGHPUTともAGLによる作業分散調整は一応確認できましたがSERVICE_TIMEの動きは控えめすぎるしTHROUGHPUTにしてもオンラインチックに改修したSQLでは調整がダメダメです。そこで負荷生成シェルとJMeterテスト・プランのSQLリクエスト投入をドカンと増やしてみたいと思います。
現在のJMeterテスト・プランの設定は40スレッド・スレッドあたりリクエスト間隔30回/分と非常にユルユルです。おそらくはAGLもこんなヌルい稼働のシステムで使われること想定していないに違いありません。なのでここはスレッド数を2.5倍・リクエスト間隔を4倍、つまりSQLリクエスト投入量を一挙10倍に増やします。
負荷生成シェルは現在の50並列(SQLリクエスト投入間隔1.5秒)なのでこれを100並列に増加します(このシェル単体のCPU使用率上昇は+30%程度)。
【負荷生成シェル/JMeter設定】
| 設定項目 | 負荷生成シェル | JMeterテスト・プラン |
| 投入SQL | select count() from ( select /+ FULL(c) FULL(b) FULL(a) LEADING(a b c) USE_HASH(b c) */ a.NO from PDBUSER.TEST_TBL1 a,PDBUSER.TEST_TBL2 b,PDBUSER.TEST_TBL3 c where a.NO = b.NO and a.NO = c.NO and a.CLSS = b.CLSS and a.CLSS = c.CLSS and a.NAME = b.NAME and a.NAME = c.NAME and a.ADDR = b.ADDR and a.ADDR = c.ADDR order by NO desc); | </ConnCheck/InstNameGet2> select to_char(sysdate,’YYYY/MM/DD HH24:Mi:SS’) || ‘ ‘ || vi.INSTANCE_NAME from V$INSTANCE vi, (select count(*) CNT from ( select a.NO from PDBUSER.TEST_TBL1 a,PDBUSER.TEST_TBL2 b where a.NO = b.NO and a.CLSS = b.CLSS and a.NAME = b.NAME and a.ADDR = b.ADDR order by NO desc ) ) ptb |
| 並列度 | 50 → 100 | 40 → 100 |
| プロセス(スレッド)あたりSQLリクエスト投入間隔 | 1.5s | 0.5s |
検証結果
まずはサービス目標 SERVICE_TIMEから。負荷生成シェルはDBサーバ#1で実行しています。
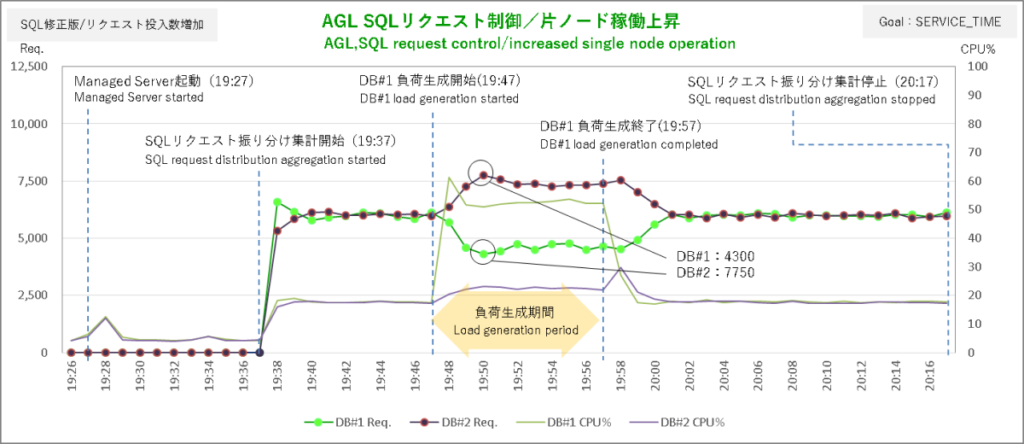
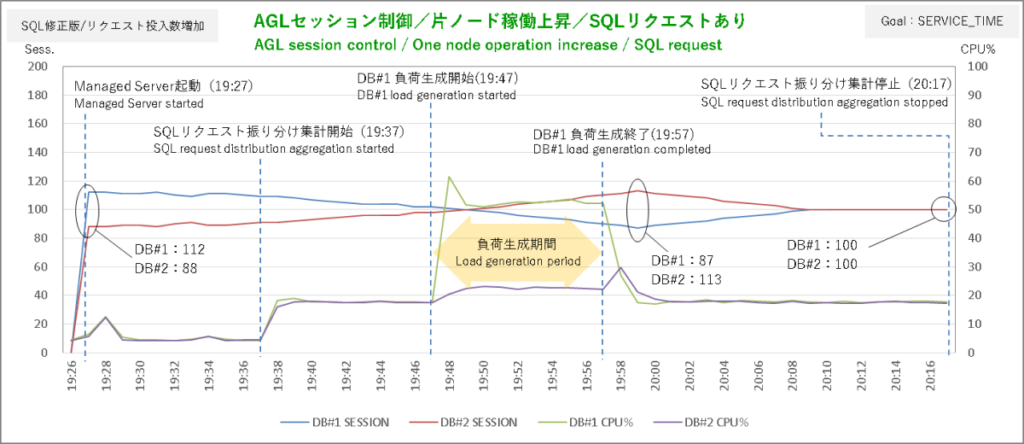
さすがに今回はガッツリSQLリクエストの振り分けを調整しています。
偏りのピークがDBサーバ#1:4300本、DBサーバ#2:7750本ですから振り分けの比率は1:2といったところで負荷生成終了後に偏りが解消するまでの流れも非常にスムーズです。なるほどこうして見るとSQLリクエストの振り分けとセッションが同じタイミングで方向を変えている(調整されている)ということがわかります。
続けてサービス目標 THROUGHPUT。負荷生成シェルはDBサーバ#1で実行しています。
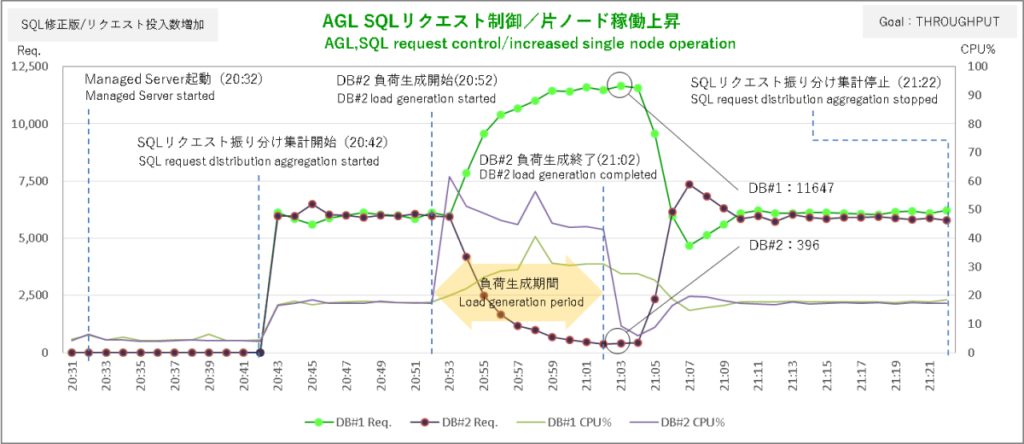
こちらも調整がキマってます。
SQLリクエスト振り分けの偏り方がダイナミックな分、サーバレベルの負荷分散という観点ではSERVICE_TIMEよりもTHROUGHPUTの方が結果良好です。
負荷生成終了後の偏り解消もSQLの稼働を重くしたバージョンが5分でこちらは4分と状況変化に対する反応も良くなって大変グッドです。
偏り解消後の酔っ払い運転みたいなジグザグラインが発生していない点も高ポイント。またセッションの状態も非常に安定しています。SQLリクエスト一発のパンチ力を減らしても手数を増やしたらTHROUGHPUTも非常に良好な結果となりました。
AGL(RCLB)動作検証 まとめ
AGL動作検証の結果をざっくりまとめるとこんな感じです。
| 項目 | サービス目標:SERVICE_TIME | サービス:THROUGHPUT |
| ロード・バランシングの目標 | 応答時間に基づいて作業要求をインスタンス(ノード)に割り当て。 ChatGptの見解だと調整の元ネタ(統計)はおそらく「Average Service Time(サービスの平均応答時間)」 | スループットに基づいて作業要求をインスタンス(ノード)に割り当て。 ChatGptの見解だと調整の元ネタ(統計)はおそらく「Calls per second」「DB time per second」「Completed work rate」あたり |
| ロード・バランシング・アドバイザ(LBA)の調整 | ・サービスの処理が軽量SQLメインでも作業分散の調整に問題なし → オンライン向き ・稼働上昇ノードから他のノードへの作業量調整の幅が控えめ → サーバレベルの負荷分散という観点ではTHROUGHPUTの方が上 | ・サービスの処理が軽量SQLメインだと低稼働時に作業分散の調整が不安定 → 低稼働のオンラインには不向き ・稼働上昇ノードから他のノードへダイナミックに作業量を調整 → サーバレベルの負荷分散という観点ではSERVICE_TIMEより効果的 |
| AGLによるDB接続テスト | LBAの調整に影響なし | 非アクティブ接続のチェックで定期的に流れる軽量SQLがLBAの調整を歪めるリスクあり → 低稼働時、サービス外部の要因によりセッションの異常な偏り発生 |
SERVICE_TIMEはノードの稼働状態に対するLBAの反応が良い(あるいは過剰な反応が抑えられている)ということは検証で確認できたのでオンライン系のシステムであればドキュメントに記述されている通りこちらの設定の方が無難かなあ、と思います。本番サイトのAGLもサービス目標はSERVICE_TIMEに設定することにします。
ただ、今回の検証ではTHROUGHPUTと短時間応答・軽量なオンライン系のSQLの低稼働時の相性がよろしくなかったですが、これは単一のSQLを一定頻度で投入していたというのがその原因の一部となっていた可能性があります。
本物のシステムでは同じオンライン系SQLにもいろいろあり、それがばらばらなタイミングで流れてくるわけですから案外THROUGHPUTでもそれほど問題にならないような気もします。SERVICE_TIMEよりもTHROUGHPUTの方がリクエスト・バランス調整時の振り分けっぷりがダイナミックなのでそれだけビジーなノードの稼働を減らせます。
サービスレベルではなくサーバレベルで稼働の分散を図りたいシステムであればTHROUGHPUTという選択は十分ありだと思います。
今回の検証ではサービス目標よってAGLがバランシングをどう調整しているのかを確認しました。RCLBのもう一つの目標である接続バランシング目標を変えたらどうなるかとか、AGLとMDSとの性能比較とか他にも検証してみたいことはいろいろありますが、前回の投稿からだいぶ時間が経ってしまっているのでAGL(のRCLB)検証は一旦ここまでにして次はノード障害時のWeb-AP-DB連携について検証したいと思います。
参考情報
<Oracle公式ドキュメント>
Oracle® Universal Connection Pool開発者ガイド 21c F37749-04(原本部品番号:F31917-04)
Oracle® Real Application Clusters管理およびデプロイメント・ガイド 12cリリース1 (12.1) B71323-07
Oracle® Fusion Middleware Oracle WebLogic Server JDBCデータ・ソースの構成と管理
11gリリース1 (10.3.6) B60997-04
※AGL(RCLB)についての情報は古いバージョンのドキュメントの方がわかりやすく書かれています。最後のリンクはNECさんとOracleさんが共同でAGLの検証を行ったホワイトペーパーで性能検証の結果や機能の説明が詳しく記述されています。
コメント