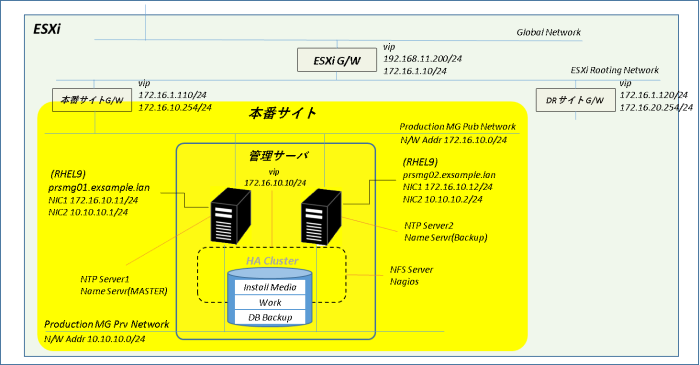
Pacemakerインストール
事前準備
クラスタ・ノード間通信用ネットワーク追加
管理サーバ#1、管理サーバ#2にネットワーク・アダプタを追加します。追加アダプタ及びN/Wインターフェースの設定値は以下の通りです。
【仮想マシン・ネットワーク・アダプタ設定】
| 設定項目 | ポートグループ |
| ネットワーク アダプタ 2 | Production MG Prv Network |
【N/Wインターフェース・IPアドレス】
| デバイス名 | 管理サーバ#1(prsmg01) | 管理サーバ#2(prsmg02) |
| ens224 | 10.10.10.1/24 | 10.10.10.2/24 |
NFS共有ディスク追加
管理サーバ#1、管理サーバ#2にディスク共有用のSCSIコントローラと共有ディスクを追加します。新規ハードディスクの設定値は以下の通りです。
| 設定項目 | サイズ | 場所 | コントローラの場所 |
| ハードディスク 2 | 100 GB | [datastore1] storage/prsmg/disk001.vmdk | SCSI Controller 1 SCSI(1:0) |
管理サーバ#1、管理サーバ#2でlsblkを実行して/dev/sdb(100 GB)が追加されたことを確認します。
【prsmg01、prsmg02で実行】
-----------------------------------------------------------------------------
lsblk
-----------------------------------------------------------------------------
【lsbln実行結果】
-----------------------------------------------------------------------------
[root@prsmg01 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 100G 0 disk
tqsda1
| 8:1 0 1G 0 part /boot
Lda2
| 8:2 0 99G 0 part
-root_vg-root
| 253:0 0 65G 0 lvm /var/named/chroot/usr/lib64/named
| /var/named/chroot/usr/lib64/bind
| /var/named/chroot/etc/named
| /var/named/chroot/etc/services
| /var/named/chroot/etc/protocols
| /var/named/chroot/etc/crypto-policies/back-ends/bind.config
| /var/named/chroot/etc/rndc.key
| /var/named/chroot/etc/named.rfc1912.zones
| /var/named/chroot/etc/named.conf
| /var/named/chroot/etc/named.root.key
| /var/named/chroot/etc/localtime
| /
-root_vg-swap
| 253:1 0 4G 0 lvm [SWAP]
Lroot_vg-var
253:2 0 30G 0 lvm /var/named/chroot/var/named
/var
sdb 8:16 0 100G 0 disk
sr0 11:0 1 11G 0 rom /mnt/cdrom
[root@prsmg01 ~]#
Pacemakerインストール
クラスタ関連パッケージはインストール・メディアはなくRed Hat High Availability チャンネルに含まれています。
管理サーバをRed Hat High Availability チャンネルに接続してパッケージをインストールすることはもちろん可能ですが、今回はインターネットに接続できないシステムでも応用が利くようにRed Hat High Availability チャンネルから管理サーバ#1にパッケージのダウンロードのみ行い、これをリポジトリ化して各管理サーバにインストールするという流れで作業を進めます。
事前準備
PCのルーティング・テーブルにはESXi内部へのルーティング情報が書き込まれているのでPCと仮想マシンの双方で通信ができますが、ESXi外部の物理ルータはこの情報を保持していないので仮想マシンにパケットを送信する(その経路にあるESXiゲートウェイにパケットを渡す)ことができません。そのため仮想マシンは物理ルータとも、物理ルータが接続されているインターネットとも通信することができません。
そこで管理サーバ#1への経路を物理ルータのルーティング・テーブルに設定して仮想マシンがRed Hat High Availability チャンネルに接続できるようにします。
【物理ルータに追加するルーティング情報】
| 宛先アドレス | サブネットマスク | ゲートウェイ |
| 172.16.10.11 | 255.255.255.255 | 192.168.11.200 |
物理ルータにルーティング情報を設定後、管理サーバ#1からRed Hatサイトの名前解決とping疎通に問題がないことを確認します。
【prsmg01で実行】
-----------------------------------------------------------------------------
nslookup www.redhat.com
ping -c 2 www.redhat.com
クラスタ関連パッケージ・ダウンロード
Red Hatリポジトリからのダウンロードの準備としてサブスクリプション・マネージャでシステムの登録を行います。
【prsmg01で実行】
-----------------------------------------------------------------------------
subscription-manager register
-----------------------------------------------------------------------------
【実行結果】
-----------------------------------------------------------------------------
[root@prsmg01 ~]# subscription-manager register
登録中: subscription.rhsm.redhat.com:443/subscription
ユーザー名: <Reh HatユーザID>
パスワード:
このシステムは、次の ID で登録されました:
登録したシステム名: prsmg01.exsample.lan
[root@prsmg01 ~]#
DVDをマウントしてダウンロード・ディレクトリとパッケージをリポジトリ化するディレクトリを作成します。ディレクトリの準備ができたらダウンロード・ディレクトリにパッケージをダウンロードしてからリポジトリ用のディレクトリにすべてコピーします。
【prsmg01で実行】
-----------------------------------------------------------------------------
# インストールメディア(DVD)をマウント
dvdmount
# ダウンロード用ディレクトリ作成
mkdir /tmp/highavailability/
# リポジトリ・ディレクトリ作成
mkdir /root/highavailability/
# クラスタ関連パッケージをダウンロード(fence-agents-allまで1行で記述)
dnf -y install --enablerepo=rhel-9-for-x86_64-highavailability-rpms --downloadonly --destdir=/tmp/highavailability pacemaker pcs fence-agents-all
# ダウンロード・パッケージ数確認
ls /tmp/highavailability | wc -l
→ 管理サーバのインストール構成であれば82
# ダウンロード・ディレクトリのパッケージをリポジトリ・ディレクトリにコピー
cp /tmp/highavailability/* /root/highavailability/
# ダウンロードしたパッケージ数とリポジトリ・ディレクトリのパッケージ数が一致することを確認
ls /root/highavailability/ | wc -l
クラスタ用リポジトリ作成
createrepo_cをインストールしてクラスタ用リポジトリとrepoファイルを作成します。
【prsmg01で実行】
-----------------------------------------------------------------------------
# createrepo_cパッケージ・インストール
dnf -y install createrepo_c
# クラスタ用リポジトリ作成
createrepo_c --repo RHEL-HA --database /root/highavailability
# クラスタ用repoファイル作成
cat > /etc/yum.repos.d/RHEL-HA.repo <<EOF
[RHEL-HA]
name=RHEL highavailability packages
baseurl=file:///root/highavailability
gpgcheck=0
enabled=1
EOF
# リポジトリ・リストを出力
dnf repolist
→ RHEL-HAが含まれていることを確認
# リポジトリRHEL-HAに含まれるパッケージを出力
dnf repo-pkgs RHEL-HA list
→ 82パッケージが出力されることを確認
管理サーバ#1へのパッケージ・インストール
作成したクラスタ用リポジトリからpacemaker、pcs、fence-agents-allの各パッケージをインストールします。
【prsmg01で実行】
-----------------------------------------------------------------------------
# クラスタ関連パッケージ・インストール
dnf -y install --disablerepo=* --enablerepo=RHEL-HA pacemaker pcs fence-agents-all
パッケージのインストールが正常に終了したらクラスタ用リポジトリとrepoファイルを管理サーバ#2に転送します。
【rosmg01で実行】
-----------------------------------------------------------------------------
# クラスタ用リポジトリとrepoファイルを管理サーバ#2に転送
scp -r /root/highavailability/ prsmg02:/root/
scp /etc/yum.repos.d/RHEL-HA.repo prsmg02:/etc/yum.repos.d/
管理サーバ#1 事後作業
管理サーバ#1のシステム登録を解除します。
【rosmg01で実行】
-----------------------------------------------------------------------------
subscription-manager unregister
物理ルータに登録した管理サーバ#1のルーティング情報を削除します。
管理サーバ#2へのパッケージ・インストール
理サーバ#1から転送されたリポジトリを使用して管理サーバ#2にクラスタ関連パッケージのインストールを行います。
【prsmg02で実行】
-----------------------------------------------------------------------------
# インストール・メディア(DVD)マウント
dvdmount
# 管理サーバ#1と合わせるためcreaterepo_cインストール
dnf -y install createrepo_c
# クラスタ関連パッケージ・インストール
dnf -y install --disablerepo=* --enablerepo=RHEL-HA pacemaker pcs fence-agents-all
クラスタ構築
クラスタ構成概要
クラスタ・ネットワーク
ハートビート等のクラスタ・ノード間通信の接続(リンク)には専用ネットワークを割り当てます。また、この通信が切断されるとクラスタが停止してしまうため、本番サイトの管理用ネットワークをバックアップのリンクとして使用します。
【クラスタ・ネットワーク】
| リンク | ポートグループ | ネットワーク | IPアドレス |
| プライマリ | Production MG Prv Network | 10.10.10.0・24 | 10.10.10.1、10.10.10.2 |
| セカンダリ(バックアップ) | Production MG Prv Network | 172.16.10.0/24 | 172.16.10.11,172.16.10.12 |
fence-agents
H/Aクラスタ環境で障害や異常状態のノードを安全に隔離(フェンシング)するためにNFS共有ディスクを対象にfence_scsiエージェントを構成します。
NFS及びクラスタ・リソース
NFS及びクラスタ・リソースの構成は以下の通りです。
【NFS共有ディスク】
| Logical Volume | Volume Group | Physical Volume | マウントポイント | サイズ |
| nfs_lv1 | nfs_vg | /dev/sdb1 | /nfsdisk | 100 GB |
【NFS共有ディレクトリ】
| ディレクトリ | クライアント | クライアント・アクセス権限 | 説明 |
| /nfsdisk | – | – | NFS共有ディスク・マウントポイント |
| /nfsdisk/exports | – | – | NFSルートディレクトリ |
| /nfsdisk/exports/media | 172.16.10.0/24 | ro | メディア格納用ディレクトリ |
| /nfsdisk/exports/work | 172.16.10.0/24 | rw | 作業用ディレクトリ |
| /nfsdisk/exports/db | 172.16.10.21 172.16.10.22 172.16.10.23 | rw | DBバックアップ用ディレクトリ |
【クラスタ・リソース】
| リソース名 | リソース | 説明 |
| nfs_lvm | LVM-activate | NFS共有ディスクのLVM有効化/無効化 |
| nfsshare | Filesystem | NFS共有ディスクのファイルシステムを制御 |
| nfs-daemon | nfsserver | NFS Serverサービスを制御 |
| nfs-root | exportfs | NFSルートディレクトリ(/nfsdisk/exports)のexportfs 最上位のNFS共有ディレクトリ(fsid=0) |
| nfs-export1 | exportfs | メディア格納用ディレクトリのexportfs 管理サーバのみ書き込み可能 |
| nfs-export2 | exportfs | 本番サイト内全サーバにフリーの作業用ディレクトリのexportfs |
| nfs-db01 | exportfs | DBサーバ#1向けDBバックアップ用ディレクトリのexportfs |
| nfs-db02 | exportfs | DBサーバ#2向けDBバックアップ用ディレクトリのexportfs |
| nfs-db03 | exportfs | DBサーバ#3向けDBバックアップ用ディレクトリのexportfs |
| nfs_ip | IPaddr2 | NFS接続用クラスタ仮想IPアドレス(172.16.10.10/24) |
| nfs-notify | nfsnotify | NFS通知サービス |
事前準備
管理サーバ#1、管理サーバ#2でクラスタ作成の事前準備を行います。
まず、firewalldのサービス許可リストにhigh-availabilityサービスを追加します。
【prsmg01、prsmg02で実行】
-----------------------------------------------------------------------------
# firewallのサービス許可リストにhigh-availabilityサービスを追加
firewall-cmd --list-all
firewall-cmd --permanent --add-service=high-availability
firewall-cmd --reload
firewall-cmd --list-all
→ high-availabilityサービスが追加されたことを確認
クラスタ管理者であるhaclusterユーザのパスワードを設定します。
【prsmg01、prsmg02で実行】
-----------------------------------------------------------------------------
# haclusterアカウントのパスワード設定(prsmg01、prsmg02で同じパスワードを設定)
passwd hacluster
/etc/lvm/lvm.confを編集してクラスターのみがNFS共有ディスクのボリュームグループをアクティブにできるよう system_id_sourceに”uname”を設定します。
【prsmg01、prsmg02で実行】
-----------------------------------------------------------------------------
# /etc/lvm/lvm.conf編集
vi /etc/lvm/lvm.conf
-----------------------------------------------------------------------------
編集内容
★2500行目近辺「 # system_id_source = "none"」の次行に「system_id_source = "uname"」を追加して保存
-----------------------------------------------------------------------------
# system_id_source = "none"
system_id_source = "uname"
# Configuration option global/system_id_file.
# The full path to the file containing a system ID.
# This is used when system_id_source is set to 'file'.
# Comments starting with the character # are ignored.
# This configuration option does not have a default value defined.
ーーーーーーーーーーーーーーーーーーーーーーーーーー
# lvm systemidとuname -nの結果が一致することを確認
lvm systemid
uname -n
pcsdを起動して自動起動を有効化、NFS共有ディスクのマウントポイントを作成します。
【prsmg01、prsmg02で実行】
-----------------------------------------------------------------------------
# pcsdサービス起動
systemctl start pcsd.service
# pcsdサービス自動起動設定
systemctl enable pcsd.service
# NFS共有ディスクのマウントポイントを作成
mkdir /nfsdisk
クラスタ構築
クラスタ作成
クラスタ構築は対象サーバの記述がない限り管理サーバ#1で実行します。
最初にクラスタ・ノードの認証を行ってから管理サーバ”1、管理サーバ#2で構成されたクラスタ(mg_cluster)を作成します。
【prsmg01で実行】
-----------------------------------------------------------------------------
# クラスタ・ノード認証
pcs host auth prsmg01.exsample.lan prsmg02.exsample.lan
Username: hacluster
Password: <haclusterのパスワードを入力>
# 管理サーバ用クラスタ作成(1行で記述)
pcs cluster setup mg_cluster prsmg01.exsample.lan addr=10.10.10.1 addr=172.16.10.11 prsmg02.exsample.lan addr=10.10.10.2 addr=172.16.10.12
-----------------------------------------------------------------------------
補足
-----------------------------------------------------------------------------
mg_cluster:クラスタ名
prsmg01.exsample.lan :ノード1 サーバ
addr=10.10.10.1 :ノード1 link0 アドレス
addr=172.16.10.11 :ノード1 link1 アドレス
prsmg01.exsample.lan :ノード2 サーバ
addr=10.10.10.1 :ノード2 link0 アドレス
addr=172.16.10.11 :ノード2 link1 アドレス
各ノードで最初に指定したlink0 アドレスが優先度の高いリンクとしてクラスタ間の通信に使用されます。
(link0に障害が発生したときはlink1のリンクに切り替え)
オプションのlink_mode、link_priorityでモードや優先度の設定可能が可能です。
クラスタを起動して自動起動の有効化を設定します。
【prsmg01で実行】
-----------------------------------------------------------------------------
# 全ノードでクラスタ起動
pcs cluster start --all
# クラスタ状態確認
pcs cluster status
→ エラーが出力されていないことを確認。
→ クラスタ起動直後の「Node List」の各ノード状態は最初「UNCLEAN (offline)」だが少し時間を置くと「Online」に変化
# 全ノードでクラスタ自動起動有効化
pcs cluster enable --all
# 現在のクラスターとリソース状態表示
pcs status
→ 「Daemon Status」のDaemonがすべて「active/enabled」となっていることを確認
NFS共有ディスクの設定
NFS共有ディスクにパーティションを作成します。
【prsmg01で実行】
-----------------------------------------------------------------------------
parted /dev/sdb mklabel gpt unit % mkpart nfsdisk xfs 0 100
parted /dev/sdb p
作成したパーティションをPhysical Volume(PV)に指定してVolume Group(VG)、Logical Volume(LV)を作成します。
【prsmg01で実行】
-----------------------------------------------------------------------------
# Physical Volume作成
pvcreate /dev/sdb1
# Volume Group作成
vgcreate --setautoactivation n nfs_vg /dev/sdb1
# systemid を追加してVolume Groupの情報を表示(nfs_vgが作成結果を確認)
vgs -o+systemid
# Logical Volume作成
lvcreate -l 100%FREE -n nfs_lv1 nfs_vg
# systemid を追加してVolume Groupの情報を表示(nfs_vgの未割当サイズを確認)
vgs -o+systemid
# Logical Volumeの情報表示(nfs_lv1の作成結果を確認)
lvs
# nfs_lv1にxfsファイルシステムを作成
mkfs.xfs /dev/nfs_vg/nfs_lv1
管理サーバ#2・保護対象ディスクへのデバイス追加
管理サーバ#2からLVMのデバイスファイルにクラスタ共有ディスクのパーティション(/dev/sdb1)を追加します。
このとき管理サーバ#2が/dev/sdb1を認識していないと”No device found for /dev/sdb1.”が返されてエラーとなるので、このような場合はpartedで/dev/sdbのパーティション・テーブルを認識させてから再度 lvmdevices コマンドを実行します。
【prsmg02で実行】
-----------------------------------------------------------------------------
lvmdevices --adddev /dev/sdb1
-----------------------------------------------------------------------------
補足
-----------------------------------------------------------------------------
lvmdevicesコマンドの実行で"No device found for /dev/sdb1."と返されてしまった場合は管理サーバ#2が/dev/sdb1を認識していない可能性があります。その場合はpartedで/dev/sdb1を認識させてから再度lvmdevicesを実行します。
# lsblkでパーティション/dev/sdb1が表示されるか確認
lsblk
# 表示されなかった場合はpartedでパーティション情報を表示して認識させる
parted /dev/sdb p
# もう一度lsblkでパーティション/dev/sdb1が表示されるか確認
lsblk
NFS用ディレクトリ作成
管理サーバ#1でnfs_lv1を一度マウントしてNFS用ディレクトリを作成します。NFSの制御はクラスタ側で行うので、ディレクトリを作成したらnfs_lv1をアンマウントしてVGを非アクティブにします。
【prsmg01で実行】
-----------------------------------------------------------------------------
# /dev/nfs_vg/nfs_lv1アクティブ化
lvchange -ay /dev/nfs_vg/nfs_lv1
# /dev/nfs_vg/nfs_lv1を/nfsdataにマウント
mount /dev/nfs_vg/nfs_lv1 /nfsdisk
# NFS用ディレクトリ作成
mkdir -p /nfsdisk/exports/media
mkdir -p /nfsdisk/exports/work
mkdir -p /nfsdisk/exports/db
mkdir /nfsdisk/nfsinfo
# /dev/nfs_vg/nfs_lv1マウント解除
umount /nfsdisk
# /dev/nfs_vg/nfs_lv1非アクティブ化
vgchange -an nfs_vg
fwence_scsiエージェント構成
クラスタのフェンシングに使用するfwence_scsiエージェントを作成します。対象となるSCSIデバイスにはNFS共有ディスク・デバイス(/dev/sdb)を使用するのでまずこのデバイスのWWNを調べます。
【prsmg01で実行】
-----------------------------------------------------------------------------
ls -l /dev/disk/by-id | grep sdb | grep wwn
-----------------------------------------------------------------------------
【実行結果】
-----------------------------------------------------------------------------
[root@prsmg01 ~]# ls -l /dev/disk/by-id | grep sdb | grep wwn
lrwxrwxrwx 1 root root 9 4月 22 13:25 wwn-0x6000c290508961023c70453117d62910 -> ../../sdb
lrwxrwxrwx 1 root root 10 4月 22 15:30 wwn-0x6000c290508961023c70453117d62910-part1 -> ../../sdb1
[root@prsmg01 ~]#
/dev/sdbのWWNを指定してfwence_scsiエージェントを作成します。
【prsmg01で実行】
-----------------------------------------------------------------------------
# fence_scsiエージェント作成(1行で記述)
pcs stonith create scsi-shooter fence_scsi pcmk_host_list="prsmg01.exsample.lan prsmg02.exsample.lan" devices=/dev/disk/by-id/wwn-0x6000c290508961023c70453117d62910 meta provides=unfencing
# fence_scsiエージェント構成情報表示
pcs stonith config scsi-shooter
pcs status
→ scsi-shooterが追加され状態が「Started」となっていることを確認
クラスタ・リソース作成
LVM-activateリソース、Filesystemリソース、nfsserverリソース、NFSルート用のexportfsリソースをnfsgroupグループとして作成します。
【prsmg01で実行】
-----------------------------------------------------------------------------
# VG制御リソース作成
pcs resource create nfs_lvm ocf:heartbeat:LVM-activate vgname=nfs_vg vg_access_mode=system_id --group nfsgroup
pcs status
→ nfs_lvmリソースが作成され状態が「Started」となっていることを確認
# ファイルシステム・リソース作成
pcs resource create nfsshare Filesystem device=/dev/nfs_vg/nfs_lv1 directory=/nfsdisk fstype=xfs --group nfsgroup
pcs status
→ nfsshareリソースが作成され状態が「Started」となっていることを確認
# nfsserverリソース作成
pcs resource create nfs-daemon nfsserver nfs_shared_infodir=/nfsdisk/nfsinfo nfs_no_notify=true --group nfsgroup
pcs status
→ nfs-daemonリソースが作成され状態が「Started」となっていることを確認
# NFSルートとなるexportfsリソースを作成(1行で記述)
pcs resource create nfs-root exportfs clientspec=172.16.10.0/255.255.255.0 options=rw,sync,no_root_squash directory=/nfsdisk/exports fsid=0 --group nfsgroup
pcs status
→ nfs-rootリソースが作成され状態が「Started」となっていることを確認
リソース起動の優先ノードを設定していないため、この時点では最初に作成したscsi-shooterが管理サーバ#1、2番目以降に作成したnfsgroupの各リソースが管理サーバ#2で起動しています。
正系ノードには管理サーバ#1を使用する想定なのでlocation scoreを設定してnfsgroupが管理サーバ#1、scsi-shooterが管理サーバ#2で起動するように設定します。
【prsmg01で実行】
-----------------------------------------------------------------------------
# リソース配置・優先ノード設定
pcs constraint location nfsgroup prefers prsmg01.exsample.lan=INFINITY
pcs constraint location scsi-shooter prefers prsmg02.exsample.lan=INFINITY
pcs status
→ scsi-shooterがprsmg02.exsample.lan、nfsgroupがprsmg01.exsample.lanで起動していることを確認
NFSクライアントに提供する各共有ディレクトリにexportfsリソースを作成します。DBバックアップ用の共有ディレクトリはDBサーバのみアクセスを許可するよう各DBサーバにexportfsリソースを設定します。
【prsmg01で実行】
-----------------------------------------------------------------------------
# メディア格納用ディレクトリのexportfsリソースを作成(1行で記述)
pcs resource create nfs-export1 exportfs clientspec=172.16.10.0/24 options=ro,sync,no_root_squash directory=/nfsdisk/exports/media fsid=1 --group nfsgroup
pcs status
→ nfs-export1リソースの追加を確認
# 作業用ディレクトリのexportfsリソースを作成(1行で記述)
pcs resource create nfs-export2 exportfs clientspec=172.16.10.0/24 options=rw,sync,no_root_squash directory=/nfsdisk/exports/work fsid=2 --group nfsgroup
pcs status
→ nfs-export2リソースの追加を確認
# DBサーバ#1・DBバックアップ用ディレクトリのexportfsリソースを作成(1行で記述)
pcs resource create nfs-db01 exportfs clientspec=172.16.10.21 options=rw,sync,no_root_squash directory=/nfsdisk/exports/db fsid=3 --group nfsgroup
# DBサーバ#2・DBバックアップ用ディレクトリのexportfsリソースを作成(1行で記述)
pcs resource create nfs-db02 exportfs clientspec=172.16.10.22 options=rw,sync,no_root_squash directory=/nfsdisk/exports/db fsid=3 --group nfsgroup
# DBサーバ#3・DBバックアップ用ディレクトリのexportfsリソースを作成(1行で記述)
pcs resource create nfs-db03 exportfs clientspec=172.16.10.23 options=rw,sync,no_root_squash directory=/nfsdisk/exports/db fsid=3 --group nfsgroup
pcs status
→ nfs-db01、nfs-db02、nfs-db03リソースの追加を確認
NFS接続用のクラスタ仮想IPアドレスとNFS通知サービスを追加します。
【prsmg01で実行】
-----------------------------------------------------------------------------
# クラスタ仮想IPアドレス・リソース作成
pcs resource create nfs_ip IPaddr2 ip=172.16.10.10 cidr_netmask=24 --group nfsgroup
# NFS通知サービス・リソース作成
pcs resource create nfs-notify nfsnotify source_host=172.16.10.10 --group nfsgroup
pcs status
→ nfs_ip、nfs-notifyリソースの追加を確認
ping -c 2 172.16.10.10
→ クラスタ仮想IPアドレスにping疎通できることを確認
自動フェイルバック抑止設定
リソースをどのノードで起動させるかは location score値と現在実行しているノード上にリソースが残る量を決定するメタ属性 resource-stickinessで決まります。
nfsgroupの location score は管理サーバ#1を優先ノードとするため INFINITY(無限)に設定してありresource-stickinessのデフォルト値は 0のままなので、もし
1. 管理サーバ#1 障害停止
2. nfsgroup が管理サーバ#2フェイルオーバー
3. 管理サーバ#1 が復旧してクラスタに復帰
となった場合に location score > resource-stickinessの関係から nfsgroupは自動的に管理サーバ#1にフェイルバックしてしまいます。障害対応の観点からいえばこの挙動はあまりよろしくありません。
この nfsgroupの自動フェイルバックを抑止するために resource-stickinessにも INFINITYを設定します。
【prsmg01で実行】
-----------------------------------------------------------------------------
pcs resource meta nfsgroup resource-stickiness="INFINITY"
ESXiコンソールから管理サーバ#1を電源停止 / 電源投入してフェイルオーバー、フェイルバックが想定通りの挙動となっていることを確認します。
また、以下のコマンドでリソースの手動移動に問題がないことを確認します。
【prsmg01またはprsmg02で実行】
-----------------------------------------------------------------------------
# nfsgroupの移動
pcs resource move nfsgroup
# scsi-shooterの移動(prsmg02→prsmg01)
pcs resource move-with-constraint scsi-shooter
# scsi-shooterの切り戻し(prsmg01→prsmg02)
pcs resource clear scsi-shooter
firewalldへのNFSサービス許可
クラスタの構築が完了したら管理サーバ#1、管理サーバ#2のfirewalldのサービス許可リストにNFSサービスを追加します。
【prsmg01、prsmg02で実行】
-----------------------------------------------------------------------------
firewall-cmd --list-services
firewall-cmd --add-service=nfs --permanent
firewall-cmd --reload
firewall-cmd --list-services
管理サーバの構築は以上です。次はDBサーバを構築します。
管理サーバ構築 関連ページ
1.chrony、named
2.Pacemaker、NFS Server
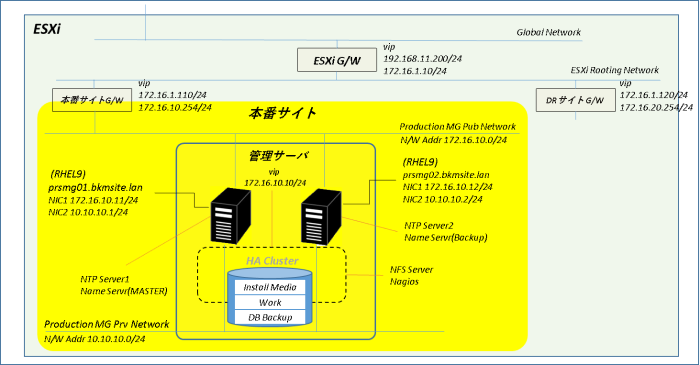
コメント
Greetings! Quick question that’s totally off topic. Do you know how to make
your site mobile friendly? My site looks weird when browsing from
my apple iphone. I’m trying to find a theme or plugin that might be able to correct this issue.
If you have any suggestions, please share. With thanks!
Sorry, but I’m just using the features provided by XServer in Japan (https://www.xserver.ne.jp), and I’m using the Cocoon theme. I’ve never really paid attention to whether my site is mobile-friendly, so I’m not sure what settings would make it display well on an iPhone. I’m really sorry I can’t be of more help.